

If you’ve just played around with Meilisearch using our quick start guide’s movies dataset, indexing your data may have taken Meilisearch only a few seconds. But if you worked with a larger dataset, it has probably taken a lot longer than that. In this article, we will review the best practices to help you index your data efficiently and speed up the indexing process.
Define your needs
Meilisearch stores data in the form of discrete records, called documents, and each document must have a unique identifier—the primary key. Documents are grouped into collections, called indexes.
To offer a search-as-you-type experience, Meilisearch needs to store and organize data in multiple manners so it can retrieve it in the most efficient way possible. Because of this, documents must undergo thorough processing before they are ready to be searched.
There are around twenty data structures per index in Meilisearch and constructing them is the most time-consuming part of the indexing process. Changing index settings may invalidate many of these data structures and require reindexing your data. Because of that, it’s usually a good idea to define the index settings before adding your documents.
Searchable attributes
By default, all document fields added to Meilisearch are searchable. However, the words present in the fields listed in the searchable attributes are the ones that require the most data structures–eleven, to be exact. A good way to speed up indexing is to make sure all the attributes in the searchable attributes list are the ones you really want to be checked for matching query words.
Let's take, for example, a document containing a field with an image URL. You probably want to display the image to the user, but I doubt that users are interested in being able to search for query terms in the URL. Don’t forget that not all displayed fields need to be searchable!
It is not only important to specify in the list of searchable attributes the fields that are actually required, but it’s also essential to avoid having meaningless, random, or unique values in the searchable fields. Imagine all those databases out there full of ‘https’, ‘www’, ‘com’, or values like ‘I77lHE’—not exactly useful when trying to find a specific product or movie 😱
Speaking of which: 🤔unique values…does that ring a bell? 💡The primary key! That’s another field you can safely remove from the searchable attributes list.
Under the hood
To better understand the importance of customizing the searchable attributes index setting, let’s take a look at the largest data structures needed for the searchable attributes. Out of the eleven we mentioned, there are three that take the longest time to build: WORD_DOCIDS, WORD_POSITION_DOCID, and WORD_PAIR_PROXIMITY_DOCIDS.
To better understand how each data structure works, we’ll use the following set of documents as examples:
{
"id": 1,
"description": "New York City is the most populous city in the USA"
},
{
"id": 2,
"description": "New York was named in honor of the Duke of York"
},
{
"id": 3,
"description": "Tel Aviv is the new most expensive city in the world"
}
In WORD_DOCIDS, each word is associated with the primary key of the documents that contain it:
“new” => [1, 2, 3]“york” => [1, 2]
In WORD_POSITION_DOCID, the keys are words together with their position in the document. The values associated with the keys are the documents where this word occupies the same position. In the documents above, id would be the attribute 0, and description the attribute 1:
new(1,0) => [1, 2]: in documents 1 and 2, the word “new” is located in attribute 1, position 0–it’s the first word of the attributedescriptionnew(1, 4) => [3]: in document 3, “new” is located in attribute 1, position 4
Finally, in WORD_PAIR_PROXIMITY_DOCIDS Meilisearch keeps track of the distance between pairs of words across all documents in an index. Terms must be within 8 words of each other to be stored, as words further away are not considered part of the same context and, therefore, not relevant.
In the example documents above, Meilisearch would store the following pairs:
newyork1 => [1, 2]newcity2 => [1]newcity3 => [3]
The numbers attached to the word pairs represent the distance between them:
- 1 means the words are next to each other
- 2 means they are separated by one word
- 3 means they are separated by two words
As you can see, each new word represents extra rows in Meilisearch’s internal data structures. Values like unique ids or URL strings can make the databases grow tremendously–and most likely unnecessarily.
Refining which fields Meilisearch should search is critical to reduce indexing time. It can also lead to greater relevance and search speed, as the results won’t be contaminated with irrelevant data.
Filterable and sortable attributes
Certain fields don’t contain any words, but might still be crucial to help your users find the results they need. This type of data might be a perfect match for filtering and sorting than regular text-based search.
Filterable attributes are attributes that can be used as filters to refine search results. You can use them to restrict search results for a particular user or to create faceted search interfaces that allow the user to narrow down the list of results according to the criteria of their choice. Boolean-type values make great filters.
Sortable attributes are attributes that can be used for sorting at search time, which allows users to decide which documents they want to see first. Numeric values are perfect for sorting.
As a rule of thumb, if your dataset contains documents with numeric and boolean field values, take the time to assess if they can be part of the filterable or sortable attributes lists.
Ranking rules
Ranking rules are responsible for the relevancy of your search results. Meilisearch contains six built-in ranking rules:
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness"
]You can also add custom rules for ascending and descending sort to this list:
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness",
"price:asc"
]Unlike sortable attributes, which are used to sort at search time, custom ranking rules are used to set a default order.
If you need this kind of default sorting, it is better to configure it beforehand. Adding a new rule after documents have already been indexed will trigger a reindexing and potentially your nerves!
Size down and batch up
Index only what you really need. Are all the columns in your database necessary? The fewer columns in your dataset, the smaller the documents. The smaller the documents, the less they will weigh, and the faster they will reach Meilisearch, which will then be able to process them sooner.
Meilisearch combines consecutive document addition requests into a single batch and processes them together. This significantly speeds up the indexing process. Since the final size of each batch will depend on how much data Meilisearch received while it was processing the latest document addition request, it is therefore encouraged to send documents in groups rather than one by one.
For the same reason, consider compressing your data. Meilisearch supports the br, deflate, and gzip compression methods. You can find more information in our documentation.
Stay up to date and keep us updated
Use the latest stable version of Meilisearch. New releases often include performance improvements that can significantly increase indexing speed.
If you experience any indexing issues, please report them! It’s key to improving the product!
Don’t trust me, trust the data
While creating some benchmarks, Many, software engineer of the Engine team, created the following graph. Please note that the indexing time is highly dependent on the size of the machine (CPUs, RAM) and the dataset: for a similar-sized dataset, you may obtain different results.
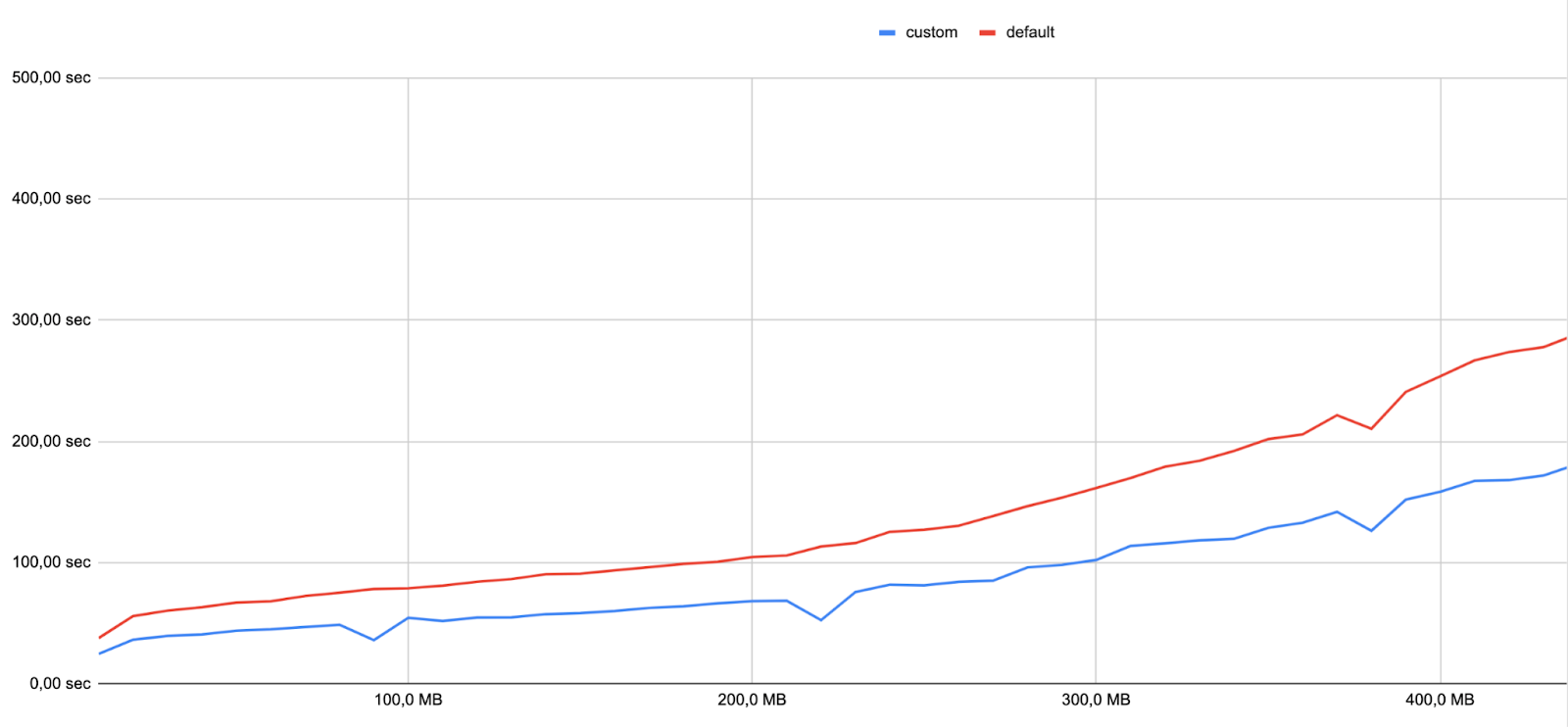
The red line represents indexing time using default settings, and the blue line represents indexing time using a custom configuration. With the same machine and dataset, we observed a 36% gain in indexing speed when using custom settings.
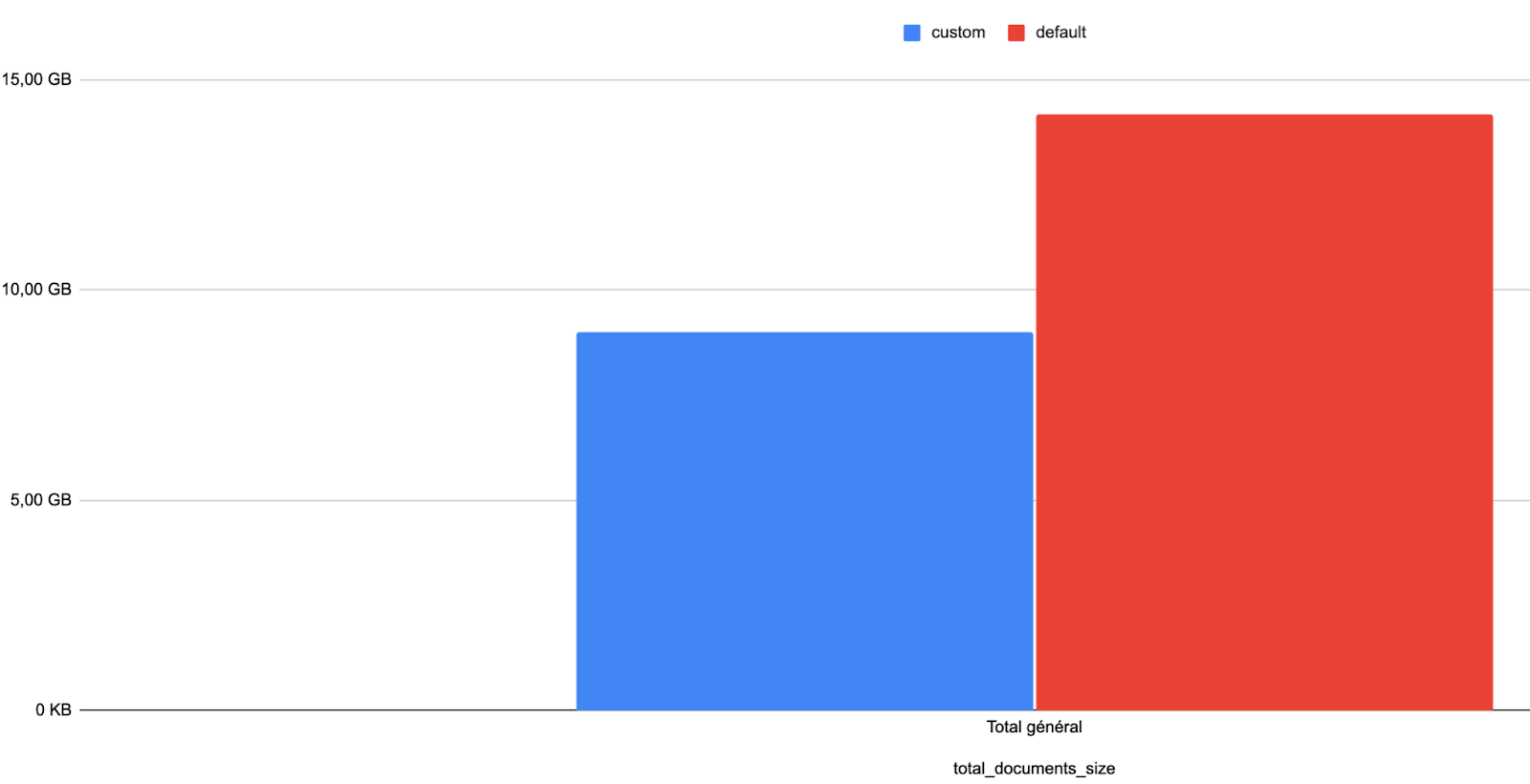
We observed similar improvements in database size, which was considerably smaller when using custom settings:
Learn more about what Meilisearch can bring to your business
And that’s all for now! We covered the best practices to speed up the indexing process. Did you know any of these tips? Have you noticed a difference in indexing speed after following them? Share your experience on our Discord!
Your feedback is key to helping us improve Meilisearch! I can't stress this enough and I never tire of repeating it, because it is the truth. Our community has built Meilisearch with us and continues to help us shape it.
Issues or product discussions on GitHub, our roadmap, our Discord server… No matter where, no matter how, we want to hear from you!