

Hey everybody! As some of you may know, I recently joined Meilisearch as a Developer Advocate. Part of my job is to help the community by answering questions, so my priority over the last few months has been to get to know Meilisearch. I believe the best way to learn new software is to use it just as any developer would: to build something. So, I set out to make a demo.
Meilisearch x MoMA
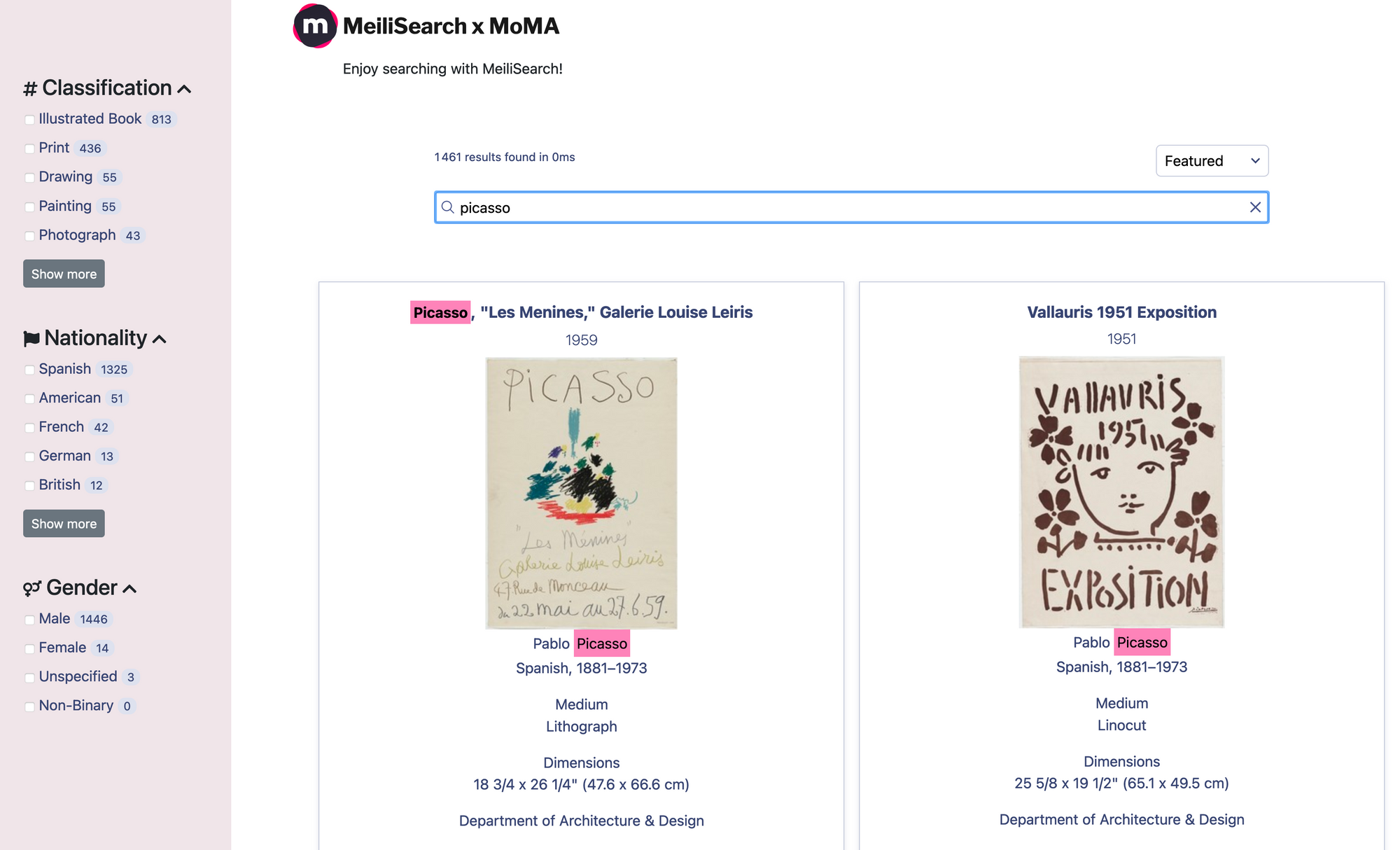
The first step was to find a nice dataset that I enjoyed working with. After several unsuccessful attempts to tame some unstructured datasets, I stumbled upon the repository of the Museum of Modern Art (MoMA). What a lucky find! They have two datasets: artists and artworks. I decided to go for the artworks dataset since it has all the essential information about each art piece: title, artist, dimensions, medium, even the artist’s biography. But the best part is that it’s available in JSON format! No conversion needed, no MongoDB dump to restore, no scraping: Meilisearch ready 😀
I used Meilisearch JavaScript to create the indexes, add the documents, and customize the settings. For the front-end, I decided to go for Instant Meilisearch combined with Vue InstantSearch as described in the meilisearch-vue repository. I’m a little lazy, so if I find a tool that provides nice results effortlessly, I will use it! Fortunately, InstantSearch provides all the front-end tools to customize the search environment at will, so you can experience the power of Meilisearch and its search-as-you-type feature with just a few lines of code. Finally, I tried to add some decent styling, but it’s not my forte 😅 I apologize in advance for the visual design!
You can see the result here.
Solving Problems
So, I had found a dataset, indexed it in a Meilisearch instance, and set up a front-end for the search. All done, right? Not exactly; now came the time to iterate and make the search results feel good.
I was lucky to find a structured JSON dataset that worked effortlessly with Meilisearch. Nevertheless, I had to make some small changes to better display the results. Since Meilisearch’s automatic highlighting doesn’t work on query results that are stored in an array, I had to convert array values into strings before adding them.
I also wanted to allow users to sort the results by date. Since the date field didn’t have a standard format, I had to retrieve the year and store it in a new `sortByDate` field. Then there was another problem: Meilisearch doesn’t support sorting at query time (at least, not yet)! To circumvent that and implement this feature, I created two more indexes with custom ranking rules desc(DateToSortBy) and asc(DateToSortBy). Every time you change the sorting option in the drop-down menu, Meilisearch is actually searching in a completely different index, but it’s so fast that the change is not visible to the human eye 🤯
Here you can see the sorting in action:
🧐 You might have noticed that I said Meilisearch doesn’t support query-time sorting yet—that’s because it’s one of the most requested features on our public roadmap, and it’s now under consideration 🥳 So if you haven’t done it yet, take a look at Meilisearch’s roadmap and vote for your favorite feature or submit your own ideas! 👉 Update note: query-time sorting was released with Meilisearch v0.22.
The most challenging part of creating this demo was working with an unknown dataset of 138,151 documents, because the large number of documents makes it difficult to know the possible values and length of the different fields. I first wanted the user to be able to filter results by `medium` (e.g. “photograph” or “paint”). That is, until I realized some of the artworks had `medium` fields that were many lines long! Take this one for example:
"H (vol. IX): Cover with lithographed manuscript text by Kliun on front; 1 lithographed illustration by Terent'ev; lithographed manuscript text. L (vol. XIII): Cover with lithographed illustration and manuscript design by Kirill Zdanevich on front; lithographed manuscript and typed text. M (vol. XIV): Cover with lithographed manuscript design and illustration on front by Kirill Zdanevich; lithographed manuscript and typed text. P (vol. XVII): Cover with lithographed manuscript design on front by Goncharova; and lithographed manuscript text by Mikhail Pustynin and Olga Olesha-Suok"
Can you imagine having this as a facet filter? Not very nice for the UI…
Close to Perfect
The easiest part of making this demo was setting up Meilisearch. Once I decided which attributes I wanted to be displayed and searchable, the rest was a piece of cake. Aside from the highlighting and sorting issues mentioned above, the last thing I changed was the attribute ranking order. By default, the attribute ranking order is generated automatically based on the attributes' order of appearance in the first document indexed. In my case, the first attribute was `title`, which meant that artwork with matching query terms in the `title` field topped the results list. This delivered decent results, but I was pretty sure I could do better.
I not only had to consider which attributes are most important for this particular dataset; I also had to think about what types of queries are more likely to be made. If a user queries for a specific art piece using its title, he will get relevant results because the words used are unlikely to be found in lots of other fields. However, if a user queries the name of a famous artist, it is very possible to find that name in an artwork title, for example as a tribute. So I decided to place `artist` at the top of the searchable attributes list. Before I made the change, this is what you would find among the first results when searching for “Van Gogh” :

As you can see, it’s an art piece created by an artist named Willem Jacob Henri Berend Sandberg where the name “Van Gogh” appears in the title, but it’s not an actual Van Gogh.
Now, after changing the order of the searchable attributes in the settings, the first result is well and truly a piece of art created by Vincent Van Gogh:

Pretty amazing how a simple change like this can impact the search results. Meilisearch is ultra relevant out-of-the-box, but it lets you tune the relevancy of the results according to your needs, and that is essential to provide an awesome experience for the end user.
An Open-Source Museum Experience
The demo source code is available on GitHub. Feel free to play with it and show me what you can do! 😁
How cool is it that we’re able to access this extraordinary catalog? Thanks to MoMA’s generosity, you can explore the museum from anywhere in the world. And now, thanks to Meilisearch, it’s only 50 milliseconds away 🚀
Photo by Robert Bye on Unsplash