

How much virtual memory can a program request from the operating system? Surely, not more than the amount of RAM installed in the machine? To which we can maybe add the amount of swap or pagefile configured? Wait — could it also depend on how much memory other processes use?
We at Meilisearch found the precise answers to these questions the hard way. In this article, we’ll share our learnings about virtual memory and how it can interact with applications in surprisingly subtle ways.
Meilisearch is an open-source search engine that aims at offering a lightning-fast, hyper-relevant search with little integration effort. It enables storing documents on disk in groups called indexes and searching those indexes to fetch the documents pertinent to each query.
Since Meilisearch v1.1 (we're now in v1.6!), we removed the limitation on both the number and maximum size of indexes. In this article, we'll share how dynamic virtual memory management was key to implementing these improvements.

Virtual memory and the limits it imposed on Meilisearch
What is virtual memory?
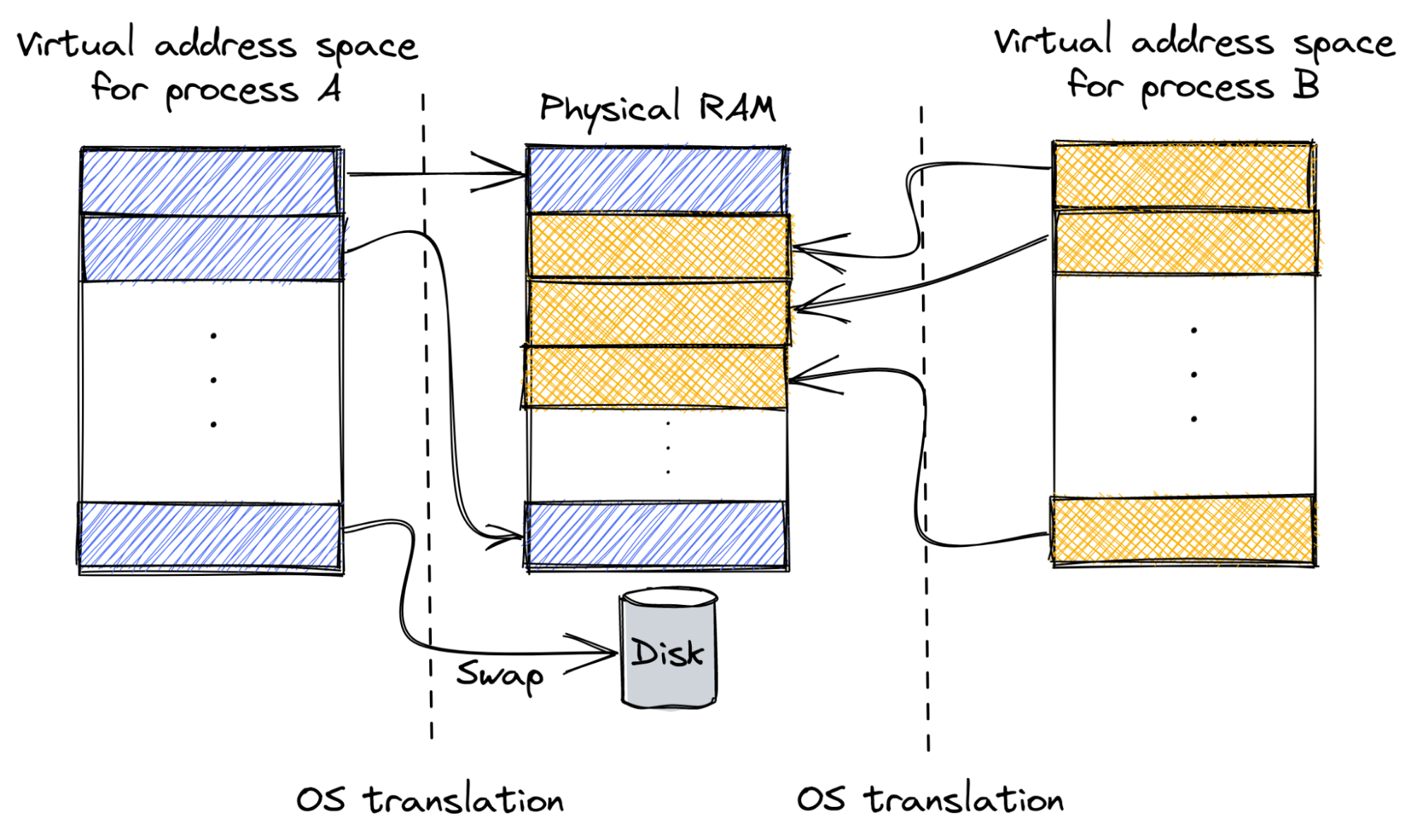
Virtual memory is an abstraction created by the operating system (OS) to manage physical memory. This abstraction allows the OS to provide running processes with a virtual address space. The virtual address space of each process is isolated from other processes. This way, a process is prevented from accidentally (or maliciously) accessing memory belonging to another process. This is in contrast to all processes having direct access to the physical memory, as was the case historically in older OSes and is still the case in some embedded systems.
The OS implements virtual memory by translating virtual memory pages manipulated by the application program to their counterparts in physical memory.
Virtual memory also enables OSes to implement a mechanism called swap (also known as pagefile.) By mapping a virtual memory page to the slower disk storage memory, to be reloaded into physical memory on the next access to that page, virtual memory also provides a way to address more memory than is physically available.
The diagram below shows an example of virtual memory for two processes, where each process can only access the parts of physical memory allocated to it by the OS. One page of process A is “swapped out” on disk and will be loaded from disk to physical memory on the next access.
Virtual memory in Meilisearch
On Unix environments, you can use command-line interface tools like htop to see how much virtual memory is used by a process. Here is the command output for a Meilisearch instance:
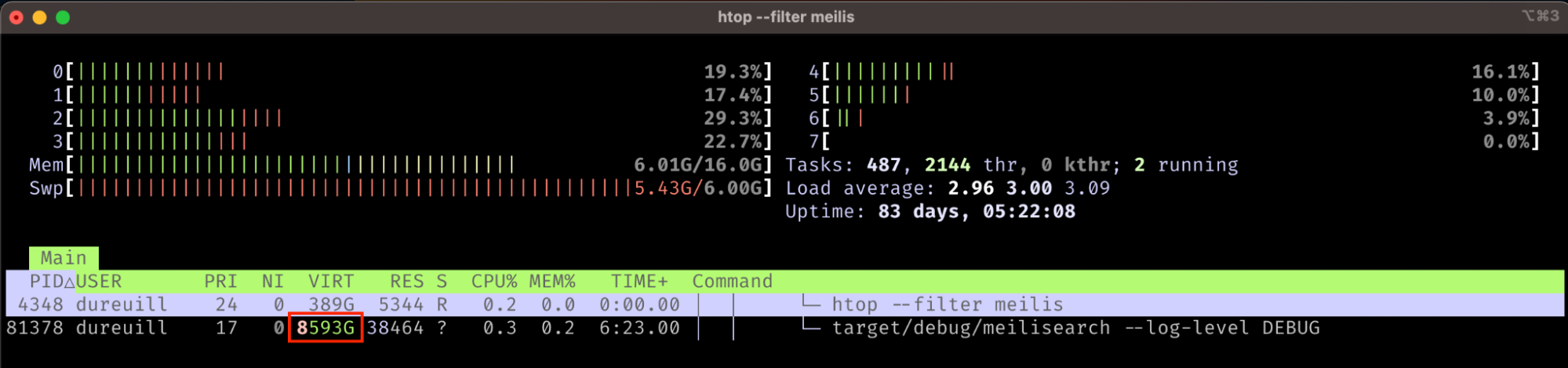
As you can see, Meilisearch is using a whopping 8593GB of virtual memory–much more than the physical memory (16GB) and disk (1000GB) available on this machine. Virtual memory can provide a process with virtually infinite memory. Note that the physical memory usage — the actual RAM — is much lower, with only 38464KB being used.
The principal responsible for Meilisearch virtual memory usage is memory mapping, where the OS maps the contents of a file to virtual memory. Meilisearch uses the LMDB key-value store to map the content of indexes stored on disk to virtual memory. This way, any read or write operation on an index file happens through the virtual memory buffer. The OS swaps the memory pages between physical memory and the disk transparently and efficiently.
Now, the thing is that such memory-mapped files can take a sizable portion of the virtual address space. When mapping a 10GB file, you essentially need a corresponding 10GB contiguous virtual memory buffer.
Furthermore, the maximum size that can be written to a file through memory mapping must be specified when creating the mapping so that the OS can determine the size of a contiguous virtual memory buffer to use for the mapping.
Getting back to our 8593GB of virtual memory used by Meilisearch, we now understand that most of it is actually used to create the memory mapping of document indexes. Meilisearch allocates that much memory to ensure these memory mappings will be large enough to accommodate the growth of the indexes on disk.
But what is the limit? How much can virtual memory grow for a process? And as a result, how many indexes can exist simultaneously, and with which maximum size?
128TB can only fit so many indexes!
Theoretically, on 64-bit computers, the virtual address space is 2^64 bytes. That's 18.45 exabytes. More than 16 million terabytes! In practice, though, the virtual address space dedicated to a process by the OS is much smaller: 128TB on Linux and 8TB on Windows.
128TB might sound like a lot. But there is a trade-off to consider between the number of indexes (N) that can be used by a Meilisearch instance and the maximum size of the indexes (M). Basically, we need N * M to remain below the 128TB limit. And with document indexes sometimes growing past hundreds of GBs, it can be a challenge.
In Meilisearch versions before v1.0, this trade-off was exposed through a --max-index-size CLI parameter. This allowed developers to define the size of the mapping of each index with a default of 100GB. With these previous versions, if you wanted to have indexes bigger than 100GB, you needed to change the value of --max-index-size to the estimated maximum size needed for an index.
So although this was not readily apparent, changing the value of the --max-index-size parameter would limit the number of indexes a Meilisearch instance could use: about 1000 indexes with a default value of 100GB on Linux and about 80 on Windows. Increasing the parameter to accommodate larger indexes would reduce the maximum number of indexes. For example, a 1TB maximum index size would limit you to 100 indexes.
So how did one decide on the value of --max-index-size? There was no straightforward answer. Because Meilisearch builds data structures called inverted indexes whose sizes depend on the characteristics of the text being indexed in non-trivial ways. The size of an index was, therefore, difficult to estimate beforehand.
Leaving this decision with subtle ramifications in the hands of the user felt like it contradicted our aim of having a simple, usable engine with good defaults. With the impending release of v1.0, we did not want to stabilize the --max-index-size parameter. Hence we decided to remove this option in v1.0. We temporarily hardcoded the memory mapping size of an index to 500GB with the plan to offer a more intuitive solution in the v1.1 release.
Enter dynamic virtual address space management.
To infinity and beyond with dynamic virtual address space management
Analogy with dynamic arrays
Let’s compare the issue at hand with fixed-size arrays. In compiled languages, fixed-size arrays require the developer to define their size at compilation time because it cannot be changed at runtime. With the deprecated --max-index-size parameter, Meilisearch users faced a similar constraint. They had to determine the optimal index size, compromising between the size and total number of indexes.
What truly made this problem unsolvable were two competing use cases for indexes:
- Storing a large number of big documents in indexes, thus having indexes reach a size of hundreds of GB;
- Storing many indexes, perhaps in the thousands (although this is often aimed at addressing multitenancy, which should be implemented with tenant tokens).
Users basically faced a dilemma: having a large index size but limiting the number of indexes or restricting index size to allow for more indexes. We had to come up with something better.
In compiled languages, developers use dynamic arrays when the size of an array cannot be known in advance. A dynamic array is a data structure composed of three bits of information:
- a pointer to a dynamically allocated contiguous array;
- the size allocated to this array, denoted as the capacity; and
- the current number of elements stored in the array.
Adding an element to a dynamic array requires checking the remaining capacity of the array. If the new elements are too big for the existing array, the array is reallocated with a bigger capacity to avoid overflow. Most system languages provide an implementation of dynamic arrays as part of their standard library (Rust, C++).
Step 1: Start small and resize as needed
Following our array analogy, a first step towards alleviating the trade-off between the number and size of indexes would be to dynamically resize indexes when their memory map is full, increasing the capacity of the memory map in the process.
In Meilisearch, we can implement a similar behavior by resizing the index when the index map is full.
We added this logic to the index scheduler responsible for managing the indexes of a Meilisearch instance. It handles changes to indexes, such as new document imports, settings updates, etc. In particular, we updated the tick function, responsible for running tasks, to handle the MaxDatabaseSizeReached error. As the name implies, this error is returned when a batch of tasks fails due to the memory map associated with an index being too small to accommodate the results of the write operations performed during that batch.
See how we implemented this in Rust:
// When you get the MaxDatabaseSizeReached error:
// 1. identify the full index
// 2. close the associated environment
// 3. resize it
// 4. re-schedule tasks
Err(Error::Milli(milli::Error::UserError(
milli::UserError::MaxDatabaseSizeReached,
))) if index_uid.is_some() => {
// Find the index UID associated with the current batch of tasks.
let index_uid = index_uid.unwrap();
// Perform the resize operation for that index.
self.index_mapper.resize_index(&wtxn, &index_uid)?;
// Do not commit any change we could have made to the status of the task batch, since the batch failed.
wtxn.abort().map_err(Error::HeedTransaction)?;
// Ask the scheduler to keep processing,
// which will cause a new attempt at processing the same task,
// this time on the resized index.
return Ok(TickOutcome::TickAgain(0));
}The error is handled by resizing the index. It is implemented in the IndexMapper::resize_index function, a simplified implementation of which is given below:
/// Resizes the maximum size of the specified index to the double of its current maximum size.
///
/// This operation involves closing the underlying environment which can take a long time to complete.
/// Other tasks will be prevented from accessing the index while it is being resized.
pub fn resize_index(&self, rtxn: &RoTxn, uuid: Uuid) -> Result<()> {
// Signal that will be sent when the resize operation completes.
// Threads that request the index will wait on this signal before reading from it.
let resize_operation = Arc::new(SignalEvent::manual(false));
// Make the index unavailable so that other parts of code don't accidentally attempt to open it while it is being resized.
let index = match self.index_map.write().insert(uuid, BeingResized(resize_operation)) {
Some(Available(index)) => index,
_ => panic!("The index is already being deleted/resized or does not exist"),
};
// Compute the new size of the index from its current size.
let current_size = index.map_size()?;
let new_size = current_size * 2;
// Request to close the index. This operation is asynchronous, as other threads could be reading from this index.
let closing_event = index.prepare_for_closing();
// Wait for other threads to relinquish the index.
closing_event.wait();
// Reopen the index with its new size.
let index = self.create_or_open_index(uuid, new_size)?;
// Insert the resized index
self.index_map.write().unwrap().insert(uuid, Available(index));
// Signal that the resize operation is complete to threads waiting to read from the index.
resize_operation.signal();
Ok(())
}As you can see, the implementation is made more complex because indexes can be requested at any time by other threads with read access. However, at its core, the implementation is similar to the capacity increase of a dynamic array.
Under this new scheme, an index would start its life with a small size — say, a couple of GBs — and would be dynamically resized upon needing more space, allowing us to address any of the two competing use cases outlined above.
We could have called it a day and gone home (well, technically no, because we’re working remotely, but that’s unrelated), but this solution still suffers from two remaining issues:
- What if we want to address both use cases simultaneously, i.e. having a lot of indexes and big-sized indexes?
- Since we depend on the
MaxDatabaseSizeReachederror to know if an index needs resizing, we discard all progress made by the batch up to this point. This means starting over again on the resized index, and basically multiplying the duration of indexing operations.
We wondered how to address these issues. In the next section, we’ll see how we handled this, as well as the new edge cases introduced by further iterations.
Step 2: Limit the number of concurrently opened indexes
The first step in addressing the issues above is finding a way to limit the total virtual memory used by all indexes. Our assumption was that we should not have all the indexes mapped in memory at the same time. By limiting the number of simultaneously opened indexes to a small number, we could afford to allocate a large portion of virtual memory to each of them.
This was implemented using a simplified Least Recently Used (LRU) cache with the following characteristics:
- Insertion and retrieval operations are done in linear time, as opposed to the usual constant time. This does not matter, considering we’re storing a very small number of elements whose keys have a performant equality comparison function (UUID).
- It can be accessed from multiple readers without blocking. In Rust terminology, it means that the data structure is
SendandSync, and its functions to retrieve an element accept a shared reference (&self). We benefit from this characteristic by putting the cache behind aRwLock. - The cache uses a generation number to track access to items. Looking for an item only entails bumping its generation number to the latest generation number known to the cache. Evicting an item when the cache is full is done by linearly searching the cache for the minimal generation number, which is the oldest accessed item. This simple implementation was possible without relying on
unsafe, which protects the implementation from the risk of memory safety errors.
With this cache, we limit the number of simultaneously opened indexes to, for example, 20. An index on a Linux machine could grow to 2TB before running out of virtual space. And running out of space would mean that the total 20 indexes would somehow be larger than 128TB on disk, which is quite a lot by today’s standards, considering that a 100TB SSD was $40,000 in 2020. If you do run into an issue caused by the size of your cumulated opened indexes being higher than 128TBs, please feel free to contact us 😎
What if we started with a big index size?
Now that the LRU allows us to accommodate memory mappings of 2TB without limiting the total number of indexes, the easy way to solve our resize performance problem is to have all indexes start with a map size of 2TB. Please note that creating a map size of 2TB does not cause a file of 2TB to be created on disk, as only the amount of documents and indexed data cause the disk file to grow. Should one index actually grow beyond 2TB, the resizing mechanism would be there to make it work. But that remains unlikely. With the cache ensuring we cannot have more than 20 indexes mapped at the same time, we can have as many indexes of arbitrary size as we want without paying any resize penalty.
The only remaining hurdle in this scheme is that for some OSes, the available virtual address space is much, much smaller than 128TB. Cue an issue opened by a user not having even 500GBs of virtual memory to allocate to a single index in v1.0. To address these edge cases, and also the matter of Windows, which only advertises 8TB of virtual memory for a process, we decided to measure at runtime the amount of virtual memory that we can memory map.
We couldn't find a way to achieve this that was both fast and portable. We decided to take advantage of the existing portability provided by LMDB (the open-source key-value store we’re using to store indexes) and also the part of our stack that relies on memory mapping. We ended up implementing a dichotomic search on the maximum map size that an index can be opened with.
By doing this dichotomic search, we measured an actual budget for allocations closer to 93TB on Linux and between 9 and 13TB for Windows (which is surprising because it is more than advertised!). The Linux difference we measure can be explained by the virtual address space being shared between all allocations from the process, not only the environment mapping. Since the allocation needs to be contiguous, a single small allocation can cause fragmentation and reduce the contiguously available virtual memory.
The implementation of dichotomic search can be found in the IndexScheduler::index_budget function. It either computes how many indexes of 2TB can be opened simultaneously or, if less than 2TB are available, how big a single index could be. For performance reasons, this dichotomic budget computation is skipped if at least 80TB (6TB for Windows) can be mapped, as we consider that we have enough space in that case.
Conclusion
The unfortunate trade-off between the number of indexes and their maximum size caused us to switch from a statically chosen max index size to a dynamic virtual address space management scheme. Meilisearch now starts by computing how many indexes of 2TB can be opened simultaneously without overflowing the virtual memory. Then, it uses an LRU cache of that many indexes opened with a map size of 2TB. Thanks to this, if an index ever goes over the 2TB limit, it is properly resized.
We had to perform this change in two steps. First, by removing the --max-index-size CLI option because we did not want to stabilize it with v1. Then, we had to design a transparent way for users to manage indexes v1.1. This is an example of the planning that went into v1.
This work also benefited from our new process to release prototypes, which allowed benevolent users such as newdev8 to help us check that the changes worked in their configuration. We are grateful for their contribution 🤗
Here’s a table summarizing the various virtual address space management schemes discussed in this article:
| Scheme | Version range | Index max size | Index max count (Linux) | Supports small address space | Index resize | Comments |
|---|---|---|---|---|---|---|
--max-index-size |
Before v1.0 | Defined at startup | 128 TB divided by --max-index-size |
Yes with proper argument value | Never | Unintuitive tradeoff |
| 500 GB | v1.0.x | 500 GB | About 200 | No | Never | Temporary for v1.0 |
| Index resize, small index size | prototype-unlimited-index-0 | 128 TB | About 12,000 with original size | Yes | Frequent | Performance regression |
| Index resize + LRU, big index size | v1.1.x and up | 128 TB | Unlimited | Yes | Never for indexes under 2 TB | Current “ideal” solution |
Here are some existing limitations in Meilisearch that we could work on to further improve the scheme:
- An index always uses one slot in the LRU regardless of its size. For indexes bigger than 2 TB, this can lead to allocation errors.
- When an index is requested, it is opened before evicting any index if the cache is full. This forces us to reserve a slot for freshly opened indexes and could conceivably cause transient allocation errors if many fresh indexes are requested simultaneously.
- This implementation requires code that reads indexes to relinquish them as fast as possible and to not open a given index twice during the same task; failure to uphold this could cause deadlocks.
- Tasks that iterate on all indexes became slower, especially on some platforms (macOS), which led us to add cache for some of them (see, for instance, this PR.)
And it’s a wrap! Join the discussion on /r/programming.
For more things Meilisearch, join us on Discord or subscribe to our newsletter. You can learn more about our product by checking out our roadmap and participating in our product discussions.