

We recently released Meilisearch v1.1. It includes the brand new /multi-search endpoint. With this endpoint, users can now send multiple search queries on one or more indexes by bundling them into a single HTTP request. Essentially, the /multi-search endpoint paves the way for federated search.
What is federated search?
Federated search, or multi-search, allows search engines to perform concurrent searches across multiple sources. This feature enables searching in indexes with different structures or types of data.
It is useful in scenarios where data represents different types of resources. Common use cases include ecommerce, CRMs, and scientific databases. Federated search allows developers to save time, effort, and resources searching through indexes separately. It also saves them the headache of designing intricate data structures that fit all documents into a single index.
By searching across multiple indexes, federated search can provide more comprehensive and accurate search results compared to traditional search.
Advantages
User experience
Federated search makes the search process faster and more convenient for end users. They can easily search for information and view results in a unified user interface, regardless of how the data is stored. By merely typing a keyword in a search bar, users can effortlessly find what they are looking for. Say goodbye to navigating through lists and menus!
By delivering a wider range of results, users can have a more comprehensive view of the available options. It enables better-informed decisions and discovery of information they may have missed otherwise. Moreover, the display of each set of results can be customized to enhance the browsing experience.
A better search experience can reduce the chances of users abandoning their session due to frustration or lack of time. It can also increase feature usage, thus improving retention and conversion for ecommerce.
Developer experience
Implementing federated search eliminates the need for complex search implementation on the front end. On top of improving the overall developer experience, it allows for optimal performance. While it was technically possible to achieve a similar user experience before, it was much more complex to implement.
In other words, federated search empowers developers to build more streamlined and efficient search experiences. This, of course, contributes to a more robust UI and UX for the end users.
Relevancy
Achieving high search relevancy can be challenging when storing different data types in the same index. Different data types may have different fields and the relevancy of a particular field can vary depending on its data type.
Keeping the data in different indexes grants you more control over the results returned to your users. Configuring each index’s settings according to its specificities allows more fine-grained tuning of the search results’ relevance.
Flexibility
Federated search can return results from different data types with different formats and schemas. This solution enables the customization of the search on a per-index basis. Developers can tailor the search behavior to the specifics of their application, while users can use search parameters such as sorting or facet filters to meet their requirements.
Federated search with Meilisearch
How to use it
With 277 votes, federated search was one of the most requested features. We are glad to finally announce the first stage of the feature.
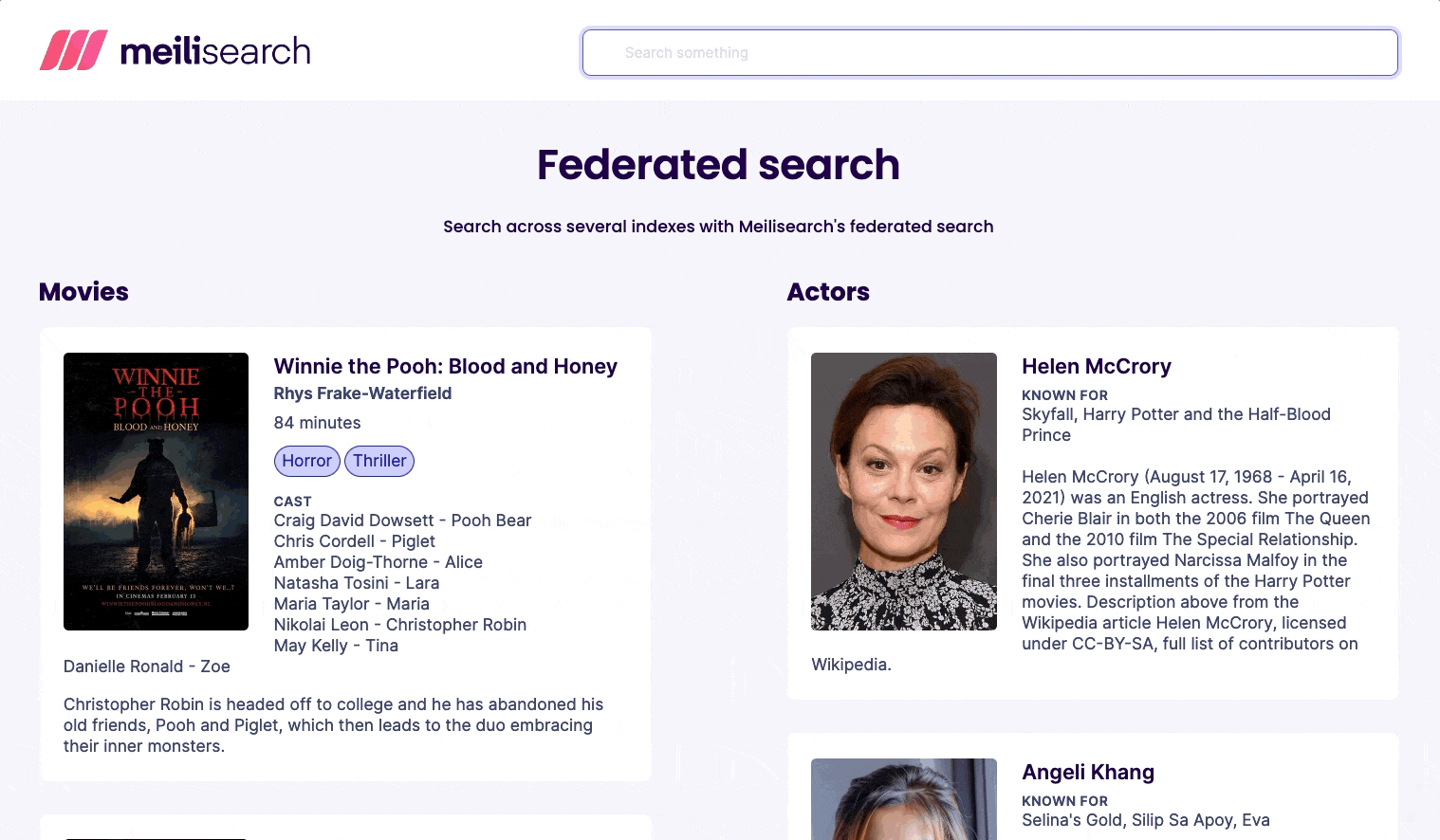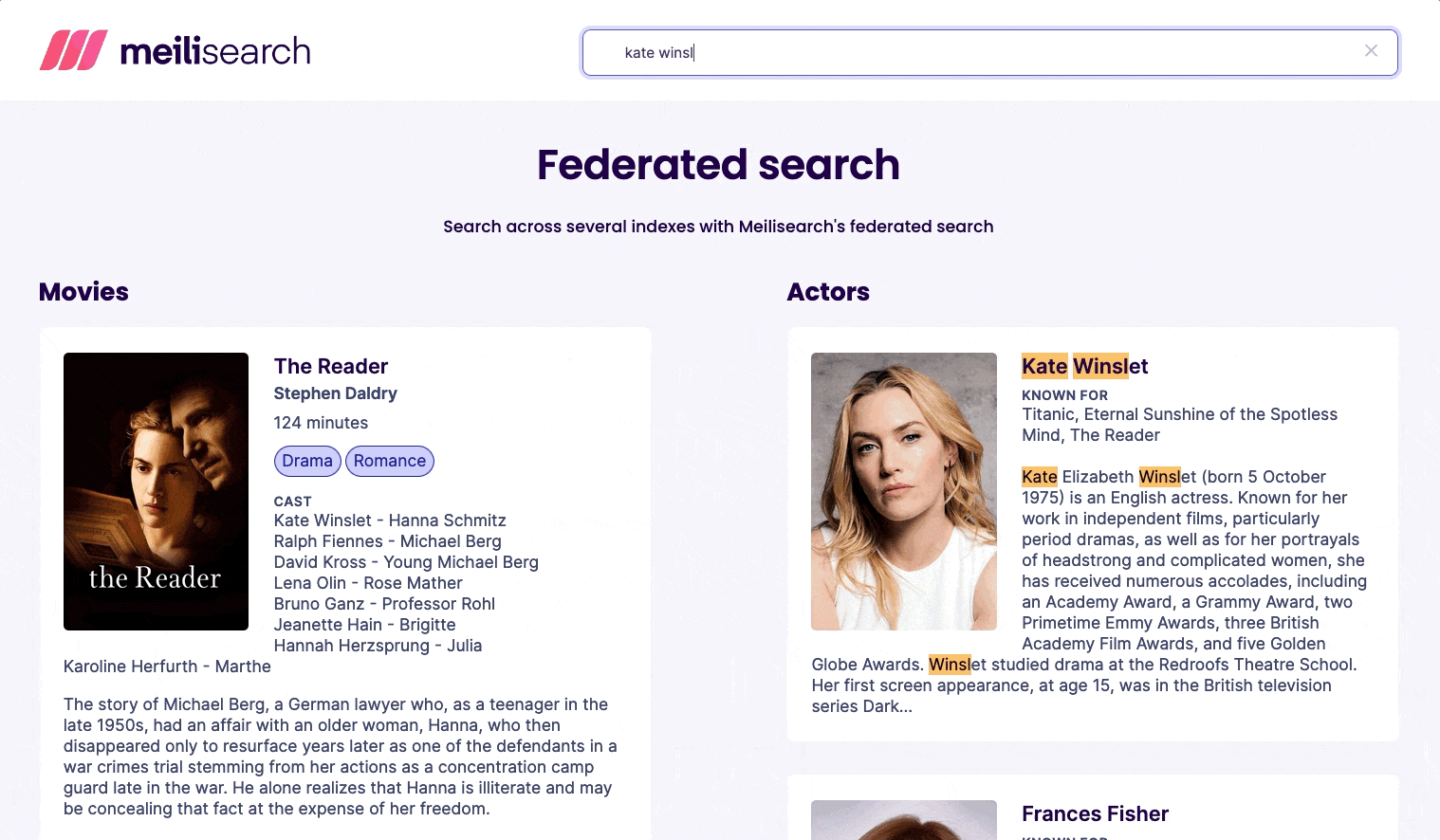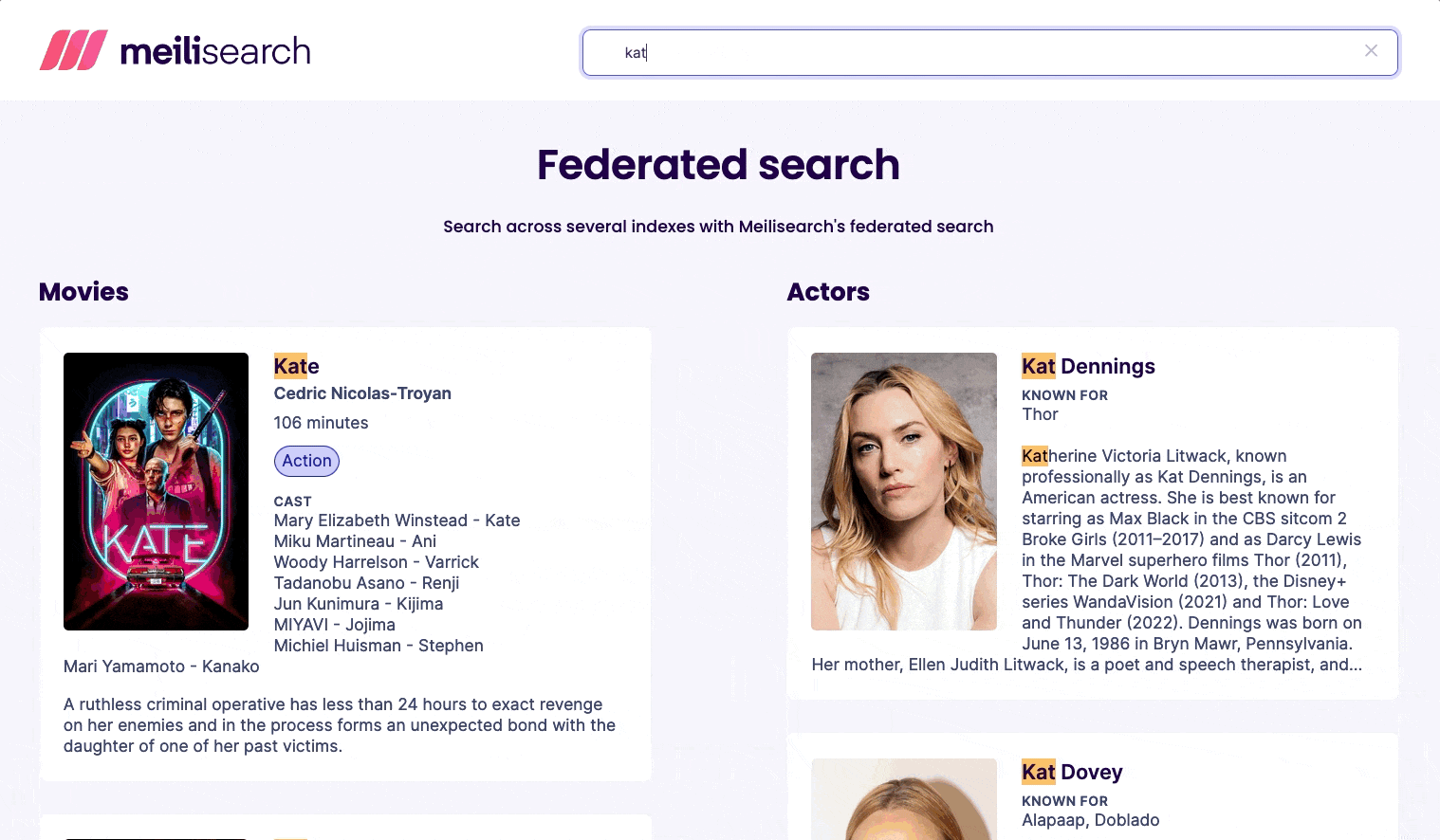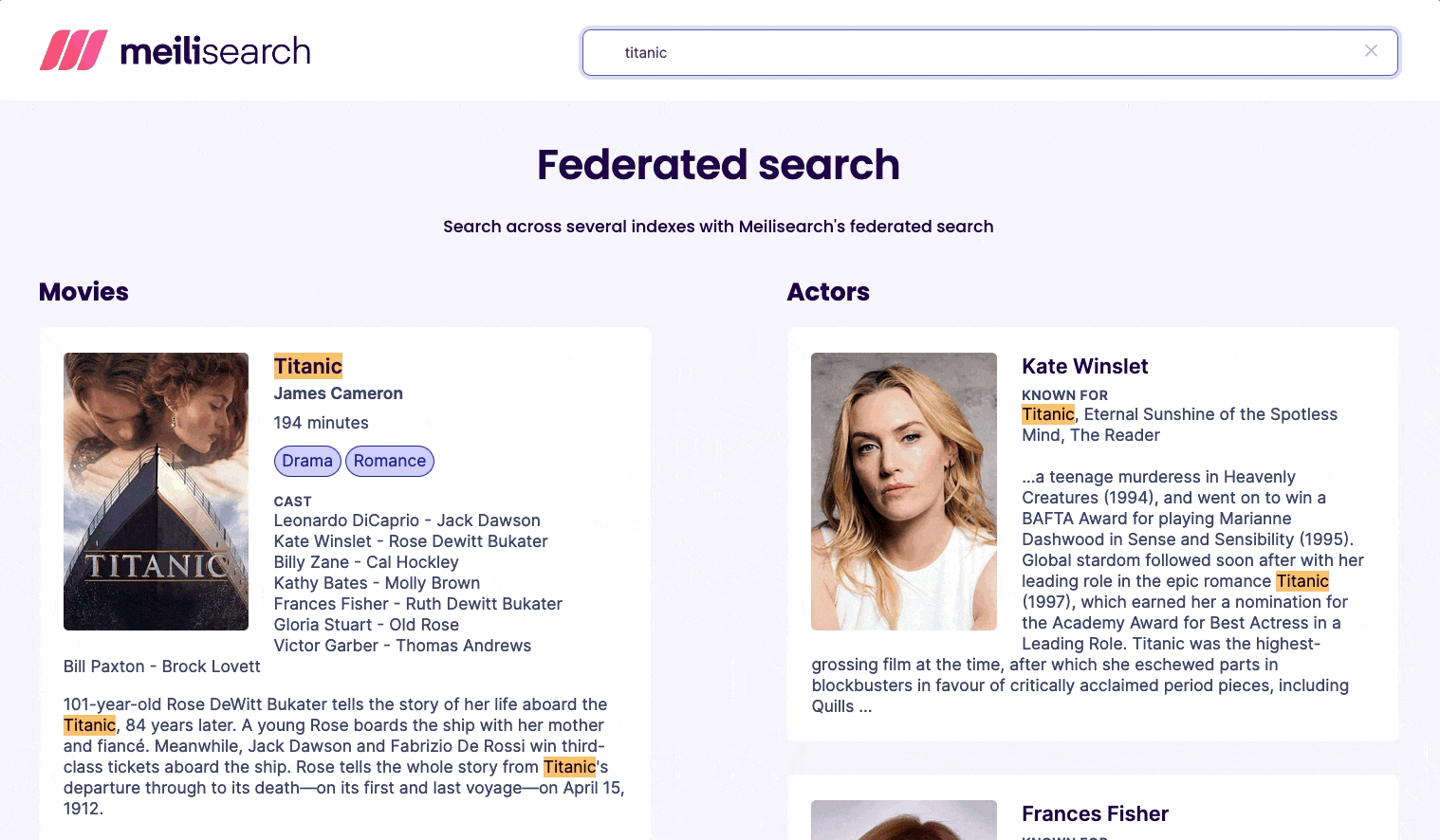
We have introduced a /multi-search route that allows searching in multiple indexes with a single HTTP request. Suppose we have two indexes: movies and actors. Using the /multi-search endpoint, we can search for the name of an actress and retrieve both her biography and movies in the search results.
Take, for instance, the following multi-search request:
curl \
-X POST 'http://localhost:7700/multi-search' \
-H 'Content-Type: application/json' \
--data-binary '{
"queries": [
{
"indexUid": "movies",
"q": "Kate Winslet",
"limit": 1
},
{
"indexUid": "actors",
"q": "Kate Winslet",
"limit": 1
}
]
}'The response will include a set of search results for each index searched:
{
"results": [
{
"indexUid": "movies",
"hits": [
{
"title": "The Reader",
"overview": "The story of Michael Berg, a German lawyer who, as a teenager in the late 1950s, had an affair with an older woman, Hanna, who then disappeared only to resurface years later as one of the defendants in a war crimes trial stemming from her actions as a concentration camp guard late in the war. He alone realizes that Hanna is illiterate and may be concealing that fact at the expense of her freedom.",
"crew": [...],
"cast": [
...
{
"character": "Hanna Schmitz",
"name": "Kate Winslet",
"profile_path": "/e3tdop3WhseRnn8KwMVLAV25Ybv.jpg"
},
...
]
}
],
// other search results fields: processingTimeMs, limit, ...
},
{
"indexUid": "actors",
"hits": [
{
"name": "Kate Winslet",
"known_for": [
"Titanic",
"Eternal Sunshine of the Spotless Mind",
"The Reader"
],
"birthday": "1975-10-05",
"deathday": null,
"biography": "Kate Elizabeth Winslet (born 5 October 1975) is an English actress. Known for her work in independent films..."
}
],
// other search results fields: processingTimeMs, limit, ...
}
]
}
As you can see, in the results array, the indexes are sorted in the same order as in the query. The response contains the usual fields that a conventional search returns along with the index UIDs. Note that, we restricted the number of documents returned to just one using the limit parameter in this example.
Demo
Try it yourself!
This demo uses two datasets: movies and actors. Each dataset is stored in its own index, has its own settings, and, as you can see in the example above, its own schema.
Since the two indexes have different schemas, they have different searchable attributes. In the movies index, you can search for a movie by its title, characters, actors, producers, directors, or movie overview.
//movies index
searchableAttributes: [
'title',
'crew.name',
'cast.name',
'cast.character',
'overview',
]The actors index allows you to search for actors by name, as well as the movies or shows they are most known for, and by keywords found in their biographies.
//actors index
searchableAttributes: ['name', 'known_for', 'biography']The full list of settings, dataset, and code are all available on GitHub, so feel free to explore them on your own. Don't hesitate to play around with the settings to customize the behavior to your needs. If you have ideas for improving the demo, like adding facets, don't hesitate to submit a pull request. All contributions are welcome!
What’s coming up next?
As mentioned above, the current release only includes the first iteration of our federated search feature. Our ultimate goal is to provide the hidden gem of federated search: being able to search multiple sources and aggregate results in a single list. Instead of having a response with a set of search results for each index searched, all the search results would be compiled into one list, sorted according to the ranking rules and settings of your choice.
Of course, the current behavior of search result sets separated per index would remain available. In fact, it would allow choosing between separate or aggregated results. There is an ongoing discussion about this subject on GitHub. Your participation would be most welcome. Your input is highly valuable to our team and would be greatly appreciated!
Conclusion
We are excited to deliver this first iteration of federated search, and we’ll be working hard to push toward aggregated search results. We couldn't have achieved this without the valuable feedback and insights provided by our developer community. Your feedback has been instrumental in helping us prioritize and shape the feature to meet your needs.
If you're interested in keeping up with our progress, we encourage you to check out our product roadmap, join our discussions on GitHub, or connect with us on Discord.
As always, we are committed to providing our users with the best possible search experience and appreciate your help in achieving this goal.