

This is part 1 of a series of blog posts originally published on my personal blog.
Uniting keyword and semantic search
At Meilisearch we are working hard on hybrid search, mixing the widespread keyword search algorithm with the not-so-common semantic search. The former is very good at exact matching, while the latter finds stuff you can describe better.
I will explain why we even talk about Meilisearch/arroy and why it is important to us. The semantic search was something new to us. The principle is quite simple: documents are associated with vectors (lists of floats), and the closer they are to each other, the closer they are semantically. When a user queries the engine, you compute the embeddings (vectors) of the query and do an approximate nearest neighbor search to get the nth closest items to the user query. Fun fact: after all this time, Annoy is still among the top competitors, so imagine when we will finally release Arroy.
Seems simple, right? Do you really think this series of blog posts will talk about a dead simple subject? Join us on a journey as @irevoire and I (@Kerollmops), with the assistance of @dureuill, work on porting this cutting-edge library to Rust.
Optimizing storage and search for high-dimension embeddings
The embeddings are something between 768 and 1536 dimensions. We have customers at Meilisearch who want to store over 100M of them. Embeddings that were not modified by any dimension reduction algorithm use 32-bit floats. This means storing this data will take between 286 GiB and 572 GiB, depending on the dimensions.
Yes, it fits in RAM, but at what cost? Storing on disk is much cheaper. Ho! And it is only the raw vectors. I assure you that doing an approximate neighbors search among all vectors in O(n) will be quite slow. So we decided to store them on disk. We have looked at many different solutions before choosing Spotify/Annoy. Initially, we used the HNSW from instant-distance Rust crate, another data structure, to do an ANNs (approximate nearest neighbors) search. However, it is not disk-based; everything lives in memory, which is unpractical.
Spotify's hyperplan trees for efficient ANNs
Spotify worked on a cool C++ library to search in enormous vector sets. The algorithm generates multiple trees that refer to the vectors. The tree nodes are random hyperplanes that split subsets of vectors in half. The root node splits the whole set of vectors in half, and the left and right branches split the subsets of vectors recursively again until the subset is small enough. When we perform an ANNs search, we go through all the root trees and decide whether to go on the hyperplanes' left or right, depending on the haystack provided. The advantage is that every node and vector is directly stored in a memory-mapped file.
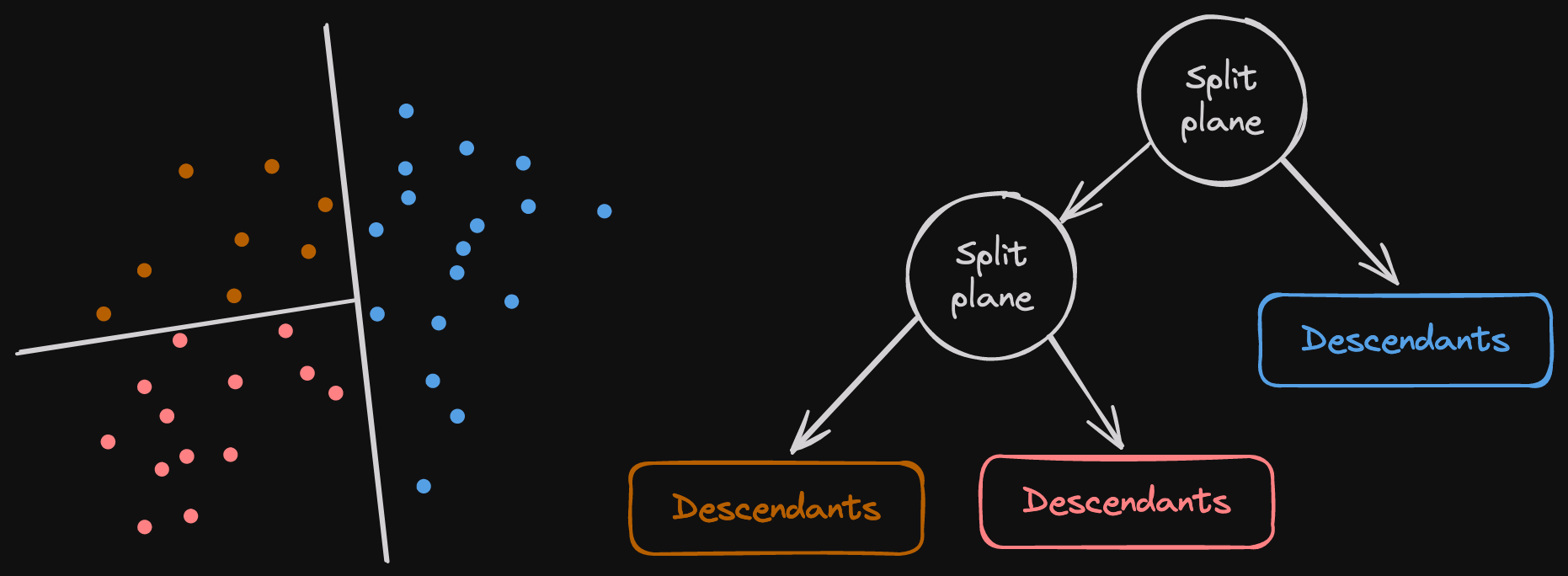
At the end of the tree, we can see the descendants' nodes. Those define the final list of leaf vectors that fit on this side of the recursive split nodes above. It is a list of unsigned integers the user provides. Annoy represents them as slices of u32s, but we decided to go with RoaringBitmaps to reduce their size. Annoy cannot compress them because they have a fun constraint: All nodes, user leaf vectors, split nodes, and descendants must be the same size to be accessible using offsets on disk.
The above image shows the way a split plane can be represented. A hyperplane splits a subset of nodes here in two dimensions, but imagine that with 768 to 1536 dimensions. Each hyperplane creates two subsets of points recursively split by another hyperplane. Once the number of points to split is small enough, we create a descendants node containing the item IDs corresponding to these points. Furthermore, the embeddings of the points are never duplicated in memory; we refer to them by their IDs.
Adapting Annoy to LMDB
So, if it works so well, why must we port it to Rust? One, because I follow the Rewrite it in Rust dogma 😛, two because this is a C++ library with a lot of horrifying hacks and undefined behaviors, and three because Meilisearch is based on LMDB, an atomic, transaction-based, memory-mapped key-value store. Moreover, since 2015, they have wanted to use LMDB, but they have yet to achieve it; it requires a lot of time to change the data structures accordingly.
LMDB uses a BTree to order the entries, and it takes more space for the intermediate data structures than annoy, which directly identifies vectors using the offset in the file. Another advantage of using this key-value store is managing incremental updates. It is easier to insert and remove vectors. Suppose you insert a vector identified by a high 32-bit integer in Annoy. In that case, it will allocate a lot of memory to store it as the dedicated offset, increasing the file size if necessary.
In Meilisearch and Arroy, we use heed, a typed LMDB Rust wrapper, to avoid undefined behavior, bugs, and stuff related to C/C++ libraries. We, therefore, use &mut and & extensively to be sure that we are not modifying the key-value store entries while keeping references inside it, and we make sure that the read-write transactions can't be referenced or sent between threads. But that will be for another story.
We first thought using this key-value store would make Arroy slower than Annoy. However, LMDB writes its pages in memory before writing them to disk, which seems much faster than directly writing into mutable memory-mapped areas. On the other hand, LMDB doesn't guarantee the memory alignment of the values that Annoy's file format permits; we'll talk about that later.
Optimizing vector handling with SIMD
The most CPU-intensive task that Arroy was supposed to do was to try to split clouds of vectors in half. This requires computing a massive number of distances in hot loops. But we read the embeddings from a memory-mapped disk. What could go wrong?
fn align_floats(unaligned_bytes: &[u8]) -> Vec<f32> {
let count = unaligned_bytes.len() / mem::size_of::<f32>();
let mut floats = vec![f32::NAN; count];
cast_slice_mut(&mut floats).copy_from_slice(unaligned_bytes);
floats
}We used Instrument on macOS to profile our program and discovered a lot of time was spent moving stuff around, i.e., _platform_memmove. The reason is that reading unaligned floats from disk is undefined behavior, so we were copying our floats into an aligned memory area as shown above. Cost: An allocation by reading plus a calling memmove.
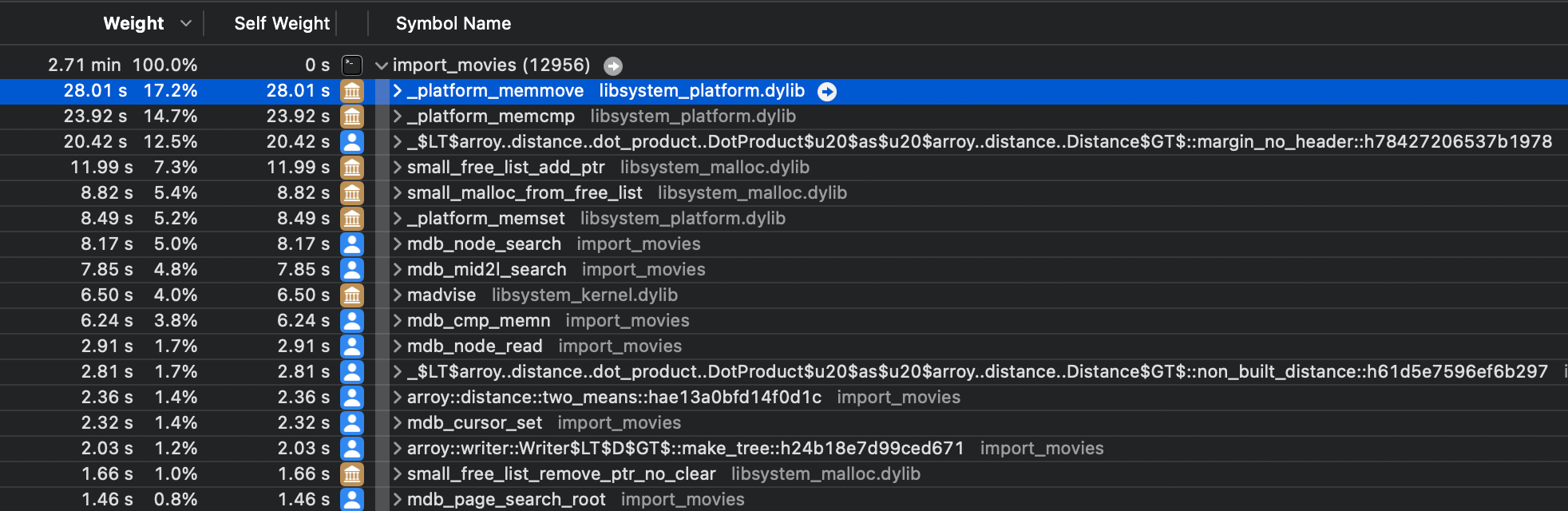
While porting the distance function from C++ to Rust, we used the Qdrant SIMD-optimized distance functions without modifying them beforehand. Although, being aware of the performance cost of reading unaligned memory, we decided to execute the distance functions on unaligned floats, making sure not to represent it as a &[f32] as it would be undefined behavior. The functions take raw slices of bytes and deal with them using pointers and SIMD functions. We unlocked performances. The distances functions were slower, but it compensated the memmoves and allocations!
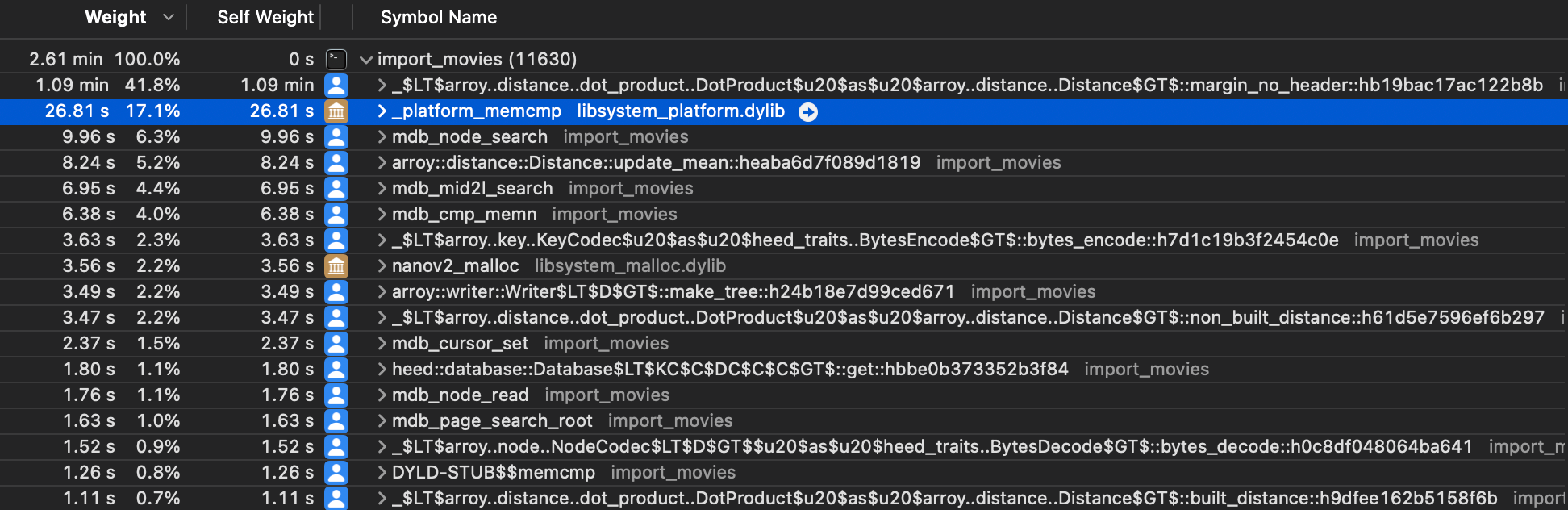
Similarly to the memmove calls, we can see that the _platform_memcmp function is taking a lot of space here. The reason is that LMDB uses this standard function to compare key bytes and decide whether a key is lexicographically located above or below another key in the tree. It is used whenever we read or write in LMDB. @irevoire drastically reduced the size of the keys and saw an important gain in performance. We further tried using the MDB_INTEGERKEY, which makes LMDB compare memory using the computer endianness, but it was complex to use and not showing significant performance gains.
Upcoming challenges
While porting this cool algorithm to Rust and LMDB, we were missing one of the most important features: Multithreading the tree building. The main reason for this missing feature is LMDB, which does not support concurrent writes to disk. It is part of the beauty of this library; writing is deterministic. We already know LMDB very well, and we will explain how we leveraged the power of LMDB in part 2 of this series and how we beat the Spotify library.
In addition to equalizing the current Annoy features, we needed more for Meilisearch. We implemented Microsoft's Filtered-DiskANN feature in Arroy. By providing the subset of item IDs we want to retrieve, we avoid searching the whole trees to fetch the approximate nearest neighbors. We will talk about this in a soon-to-be-released article.
In Meilisearch v1.6, we've optimized performance for updating only document parts, as with vote counts or view numbers. The described single-threaded version of Arroy constructs tree nodes anew for each vector adjustment. @irevoire will explore Arroy's incremental indexing in his next article, a capability not offered by Annoy.
You can comment about this article on Lobste.rs, Hacker News, the Rust Subreddit, or X (formerly Twitter).
Part 2 and part 3 of this series are now available, exploring further advancements in ANN algorithms with Rust.
Meilisearch is an open-source search engine that not only provides state-of-the-art experiences for end users but also a simple and intuitive developer experience.
For more things Meilisearch, you can join the community on Discord or subscribe to the newsletter. You can learn more about the product by checking out the roadmap and participating in product discussions.