

Oyez, oyez! A new version of Meilisearch is out and brings you a bunch of cool new features including a long-requested one: typo tolerance customization!
We have been receiving feedback from users on wanting to disable or fine-tune typo tolerance for some time. Meilisearch v0.21 introduced phrase search, which returns documents containing the exact query terms if they are enclosed within double-quotes like: “african-american poet”.
It was a big step towards meeting our users’ needs, but it was not enough. After carefully studying the matter, the time has come: the customization of typo tolerance is a reality 🎉
But hang on, what does custom typo tolerance really mean? And even more important, what does typo tolerance mean?
The good old default behavior
Meilisearch is typo tolerant, meaning it understands your search even if there are typos. But with great power comes great responsibility, which means setting boundaries to keep results relevant. This translates into the following three rules:
- No typo is allowed if the query word is less than 5 characters long
- Only 1 typo is allowed if the query word is between 5 and 8 characters long
- 2 typos are allowed if the query word is more than 8 characters long
So if you are looking for lost but accidentally type last, you wouldn't get the desired result because it’s 4 characters long.
But, typing greeecinstead of greece would retrieve the expected documents because it’s 6 characters long, so one typo is allowed.
These rules are applied by default and are part of the out-of-the-box configuration of Meilisearch, providing a powerful and relevant search. Yet, as they say, rules are meant to be broken...
Customization: a new horizon of possibilities
We know every project is different, and some users need to configure typo tolerance to suit their projects’ particularities. We hear you!
Let’s take a look at the new typo tolerance settings:
"typoTolerance": {
"enabled": true,
"minWordSizeForTypos": {
"oneTypo": 5,
"twoTypos": 10
},
"disableOnWords": [],
"disableOnAttributes": []
}
Looking at the typoTolerance object above, you can now:
- Disable typo tolerance entirely by setting
"enabled": false😱 - Disable typo tolerance partially on a set of specific terms using
"disableOnWords" - Disable typo tolerance on desired document attributes
"disableOnAttributes"
You can also fine-tune the typo tolerance settings by modifying the minimum size of a word to accept one or two typos.
In sum, you have complete control of the feature.
Try it out and see
They say a picture is worth a thousand words (I can't stop with the catchphrases, sorry); that’s why I’ve created a demo to show how different typo tolerance configurations can impact the returned search results. You can test it here.
We will be using Hakan Özler's dataset of books. I made some changes to the original dataset for demo purposes, you can find the transformed dataset on GitHub. You can search a book by its title, ISBN (the ID of the book), author, or by the words in its description.
I have created two identical indexes with different typo tolerance settings. One index uses the out-of-the-box typo tolerance settings, whereas the other uses the following:
const customTypoTolerance = {
disableOnAttributes: ['isbn'],
minWordSizeForTypos: {
oneTypo: 2,
twoTypos: 4
}
}Typo tolerance is disabled on isbn, and typos are allowed on shorter words: one typo for words that are 2 and 3 characters long, two typos for any longer word.
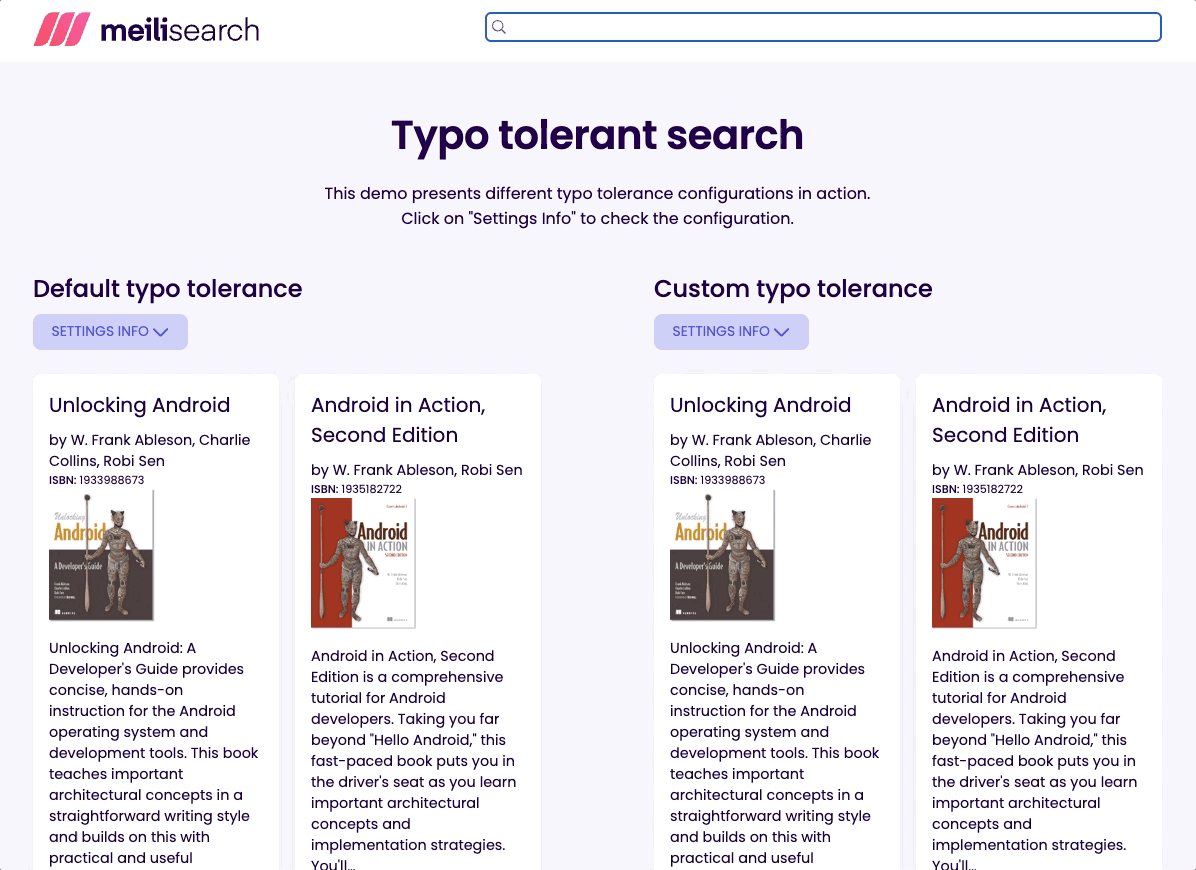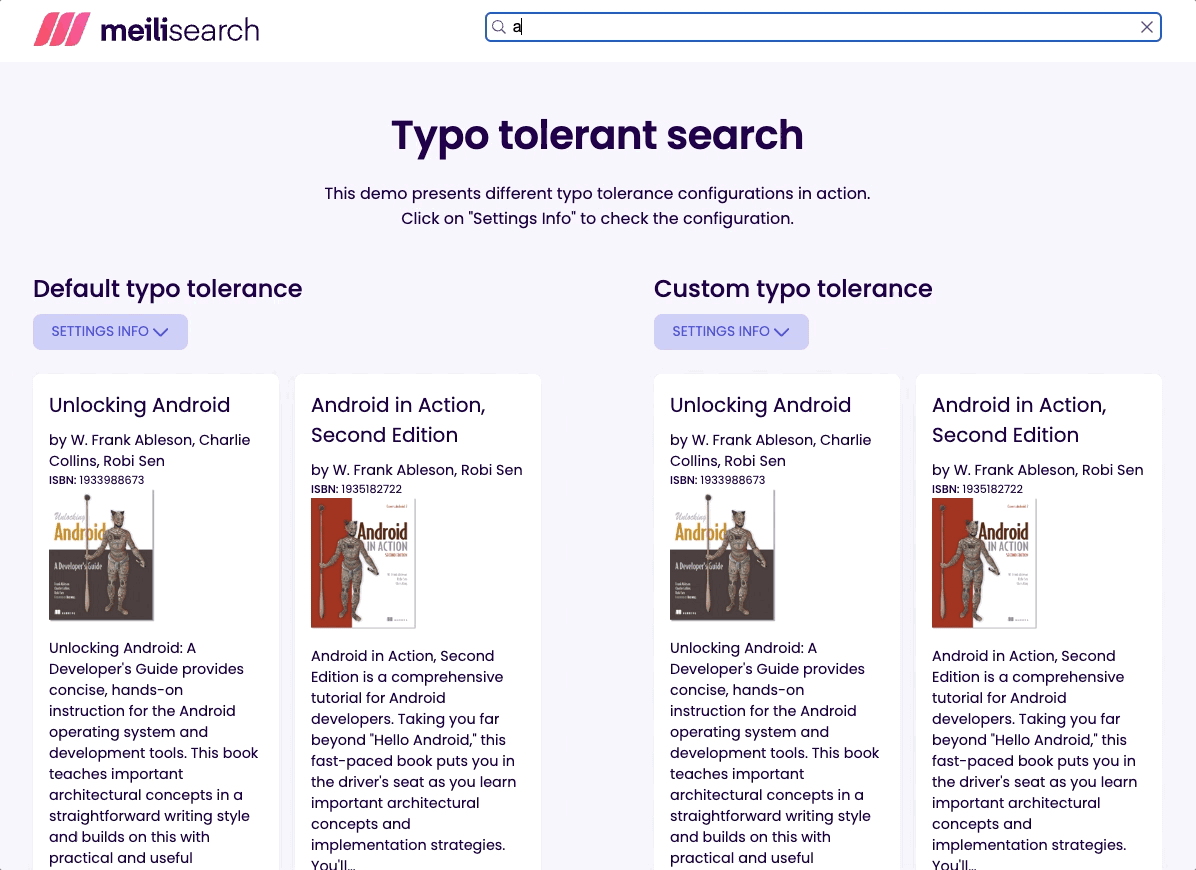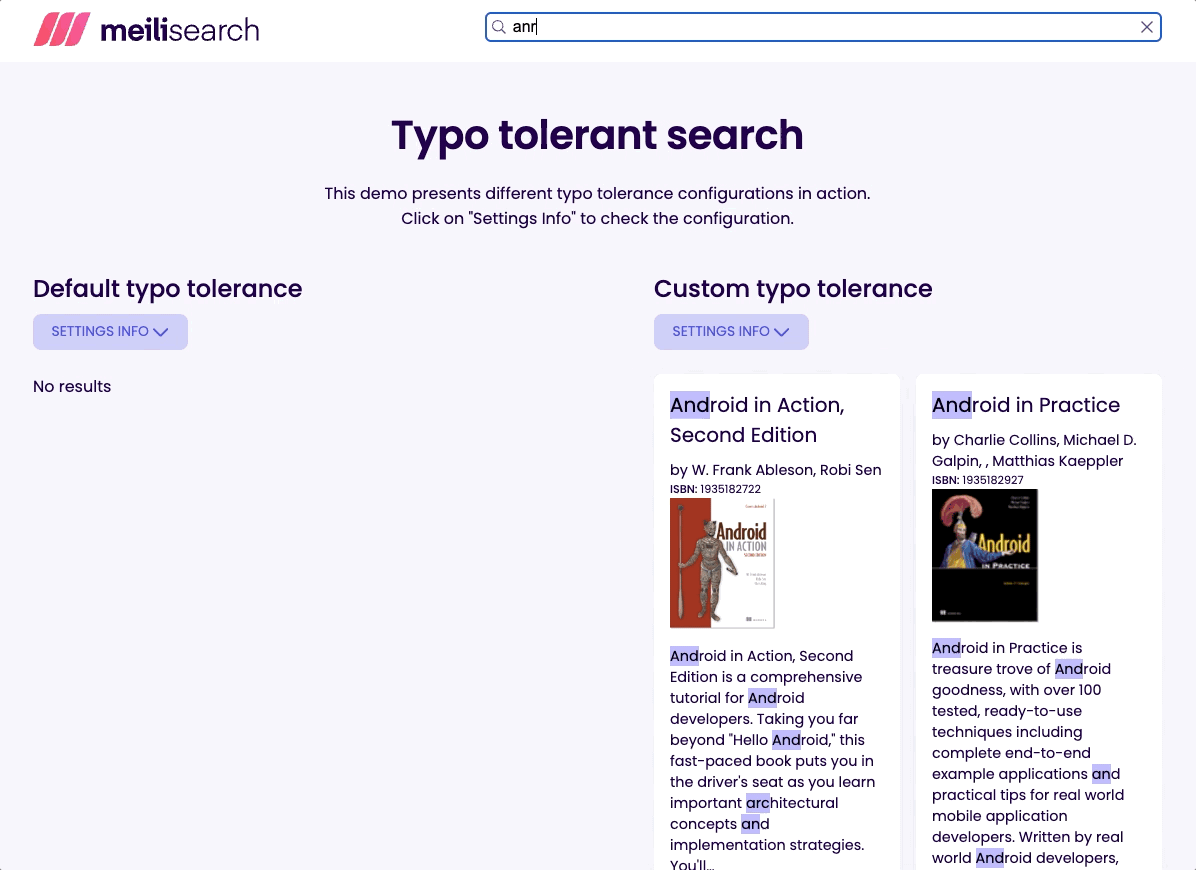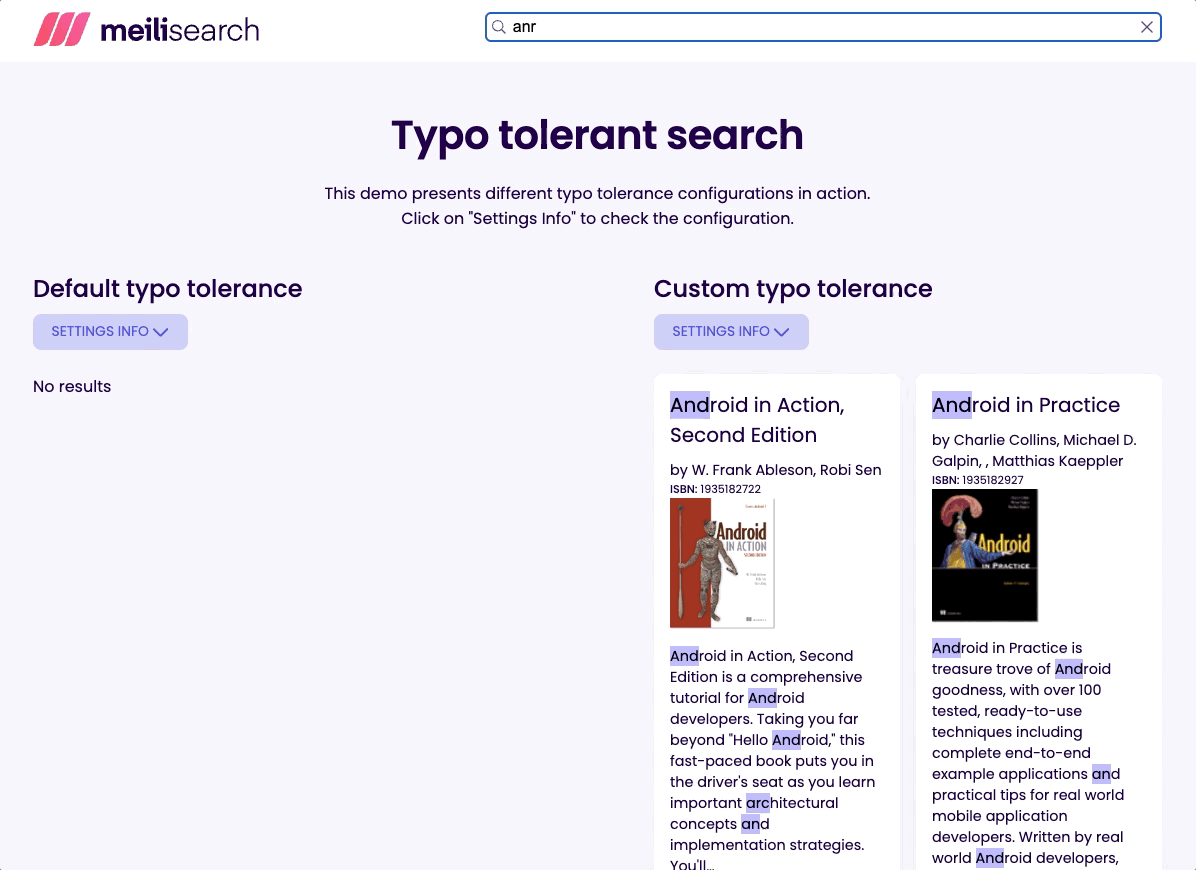
It's usually better to provide the end-user with some results than with none. That’s why I set the threshold to the minimum recommended. Try typing flx and see what happens!
Sometimes, however, it is preferable to return only exact matches. For example when searching documents by their unique identifier. The ISBN is precisely that: the ID of a book. Therefore, I disabled the typo tolerance on the isbn attribute.
Let’s try to find a book called “Well-Grounded Rubyist” by its ISBN; type 1933988657 into the search bar.
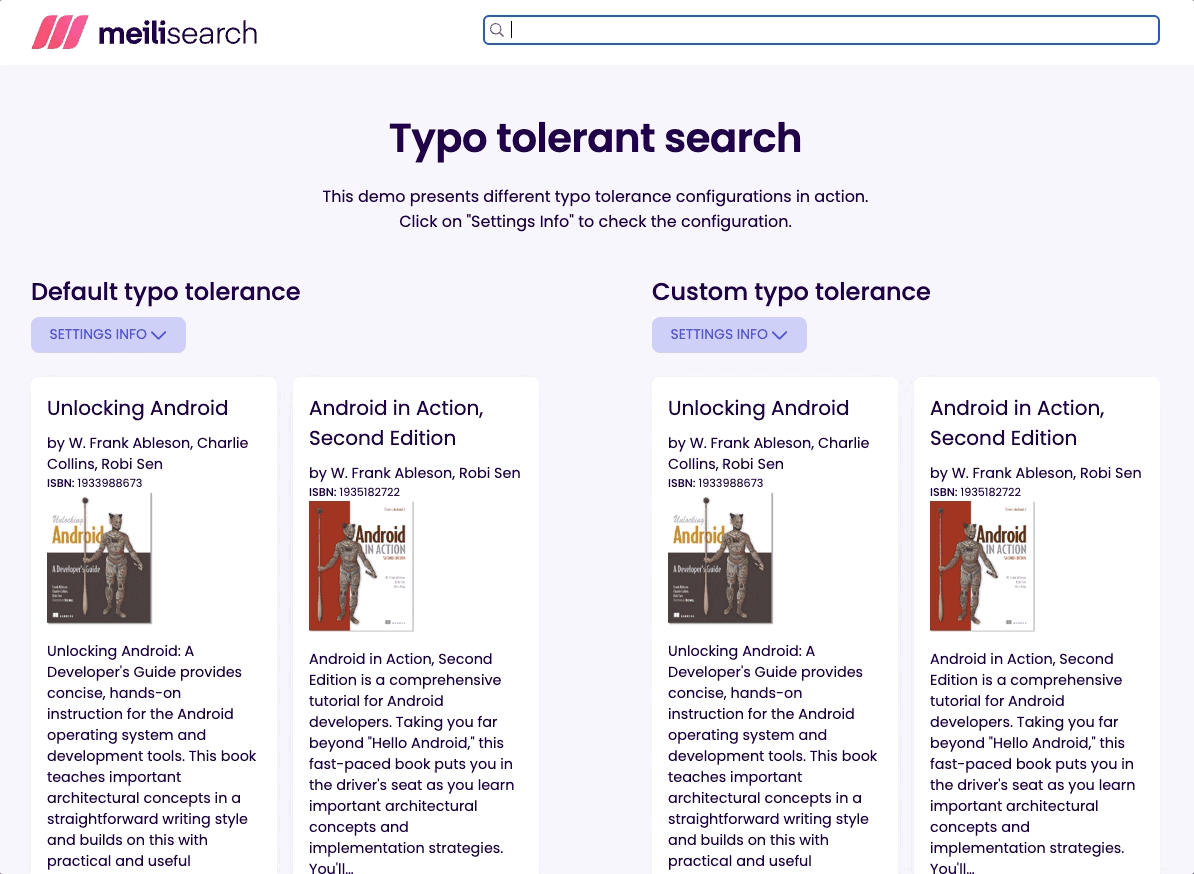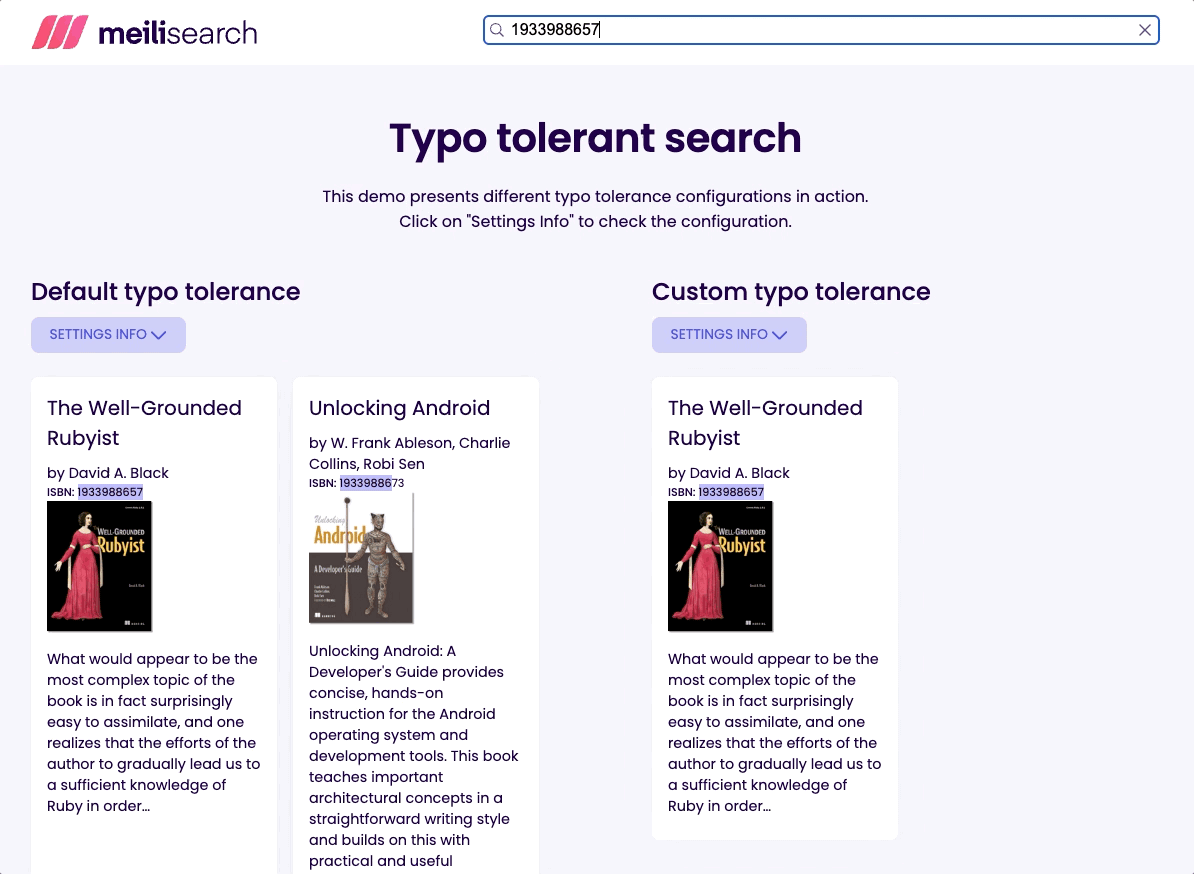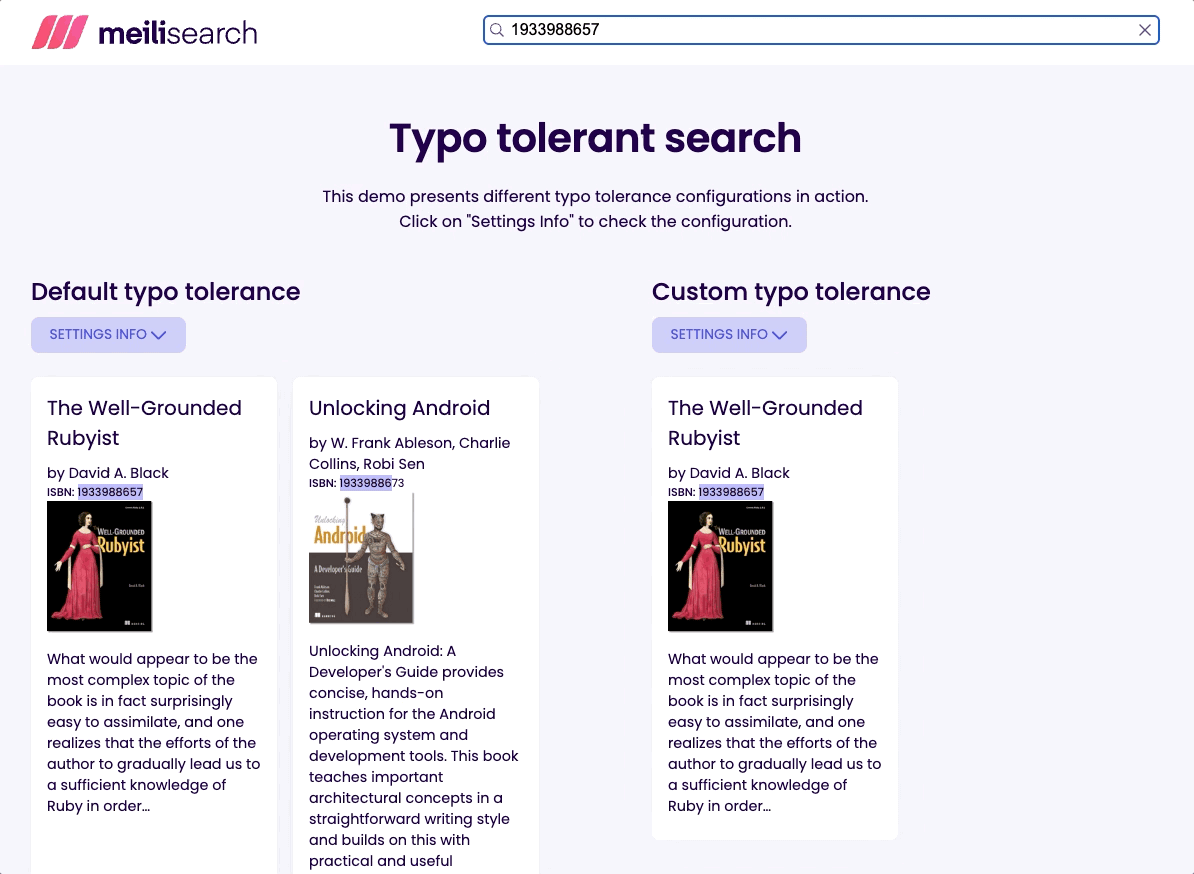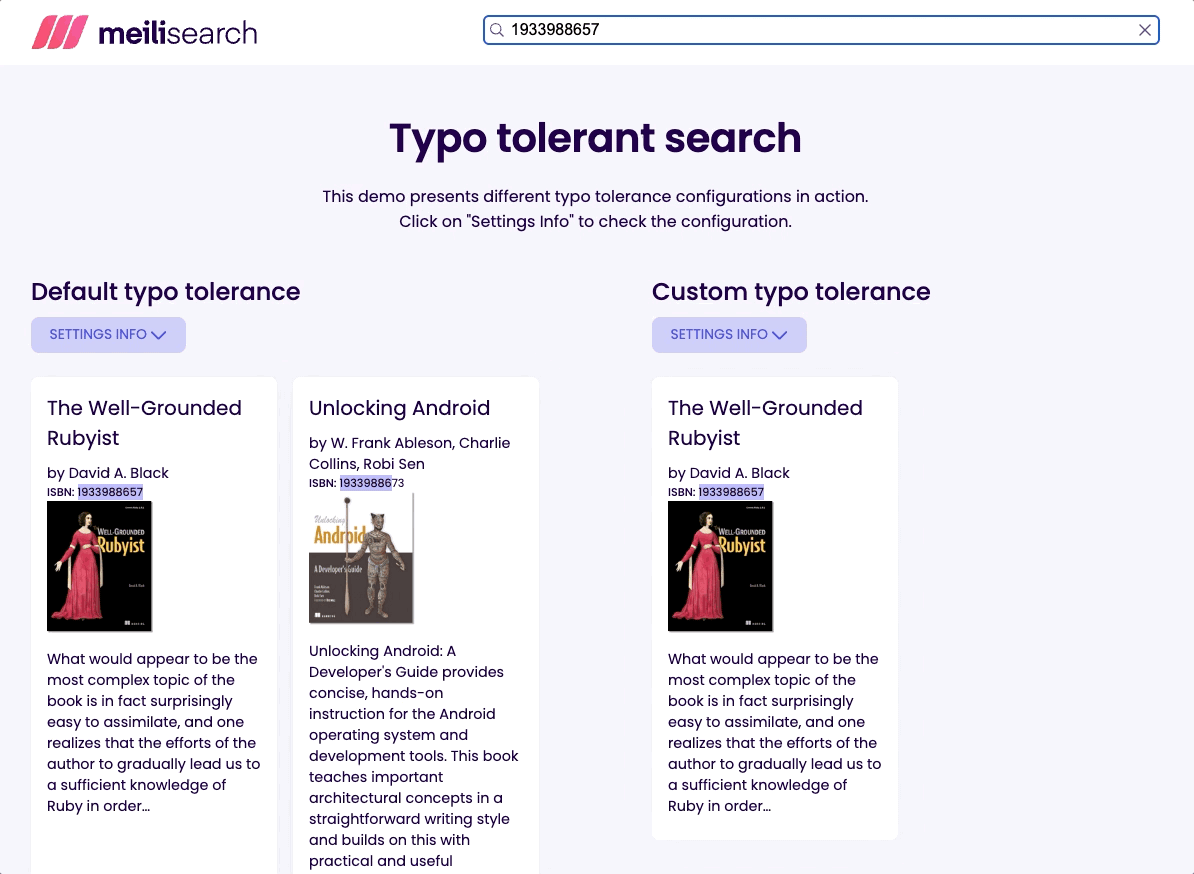
As you can see, we get the desired book with both settings. However, we get more than one result when typo tolerance is enabled. Searching for an invalid ISBN like 1933988676 still returns results when typo tolerance is enabled; this can be confusing and misleading.
Conclusion
I didn’t disable the typo tolerance on any word because I did not deem it necessary given this dataset, did you? If you want to make some modifications and try to get more relevant results, be my guest: you can find the code on GitHub.
But, if you like real challenges, I've got one for you. Literal, an online platform for book readers, uses Meilisearch to search through bookshelves. They have been kind enough to share the recipe they've been using to deliver relevant search results:
{
"displayedAttributes":[
"id",
"title",
"workId",
"authors",
"categories",
"popularity"
],
"searchableAttributes":[
"authors",
"title",
"categories"
],
"filterableAttributes":[
"isbn10",
"isbn13",
"language"
],
"distinctAttribute":"workId",
"rankingRules":[
"words",
"typo",
"popularity:desc",
"proximity",
"attribute",
"sort",
"exactness"
]
}
Can you come up with a better configuration? Can you think of the perfect typo tolerance settings to enhance the relevancy?
As you may have noticed, we take user feedback very seriously. Please don’t hesitate to check our public roadmap and upvote for any feature you'd like to see in future versions or submit a new feature idea. You can also check our product repo and make a suggestion or join an existing discussion on improving the product.
If you like Meilisearch and want to support us, a star on GitHub means a lot 🥰