

What is a vector?
Vectors are mathematical entities that possess both magnitude and direction. This ability to not only convey how much (magnitude) but also in which direction, makes them powerful tools for representing and manipulating different types of complex data.
Vectors are often pictured as arrows pointing in a certain direction within a space, but they can also be translated into numbers. Representing vectors as numerical values makes it easier to work with them mathematically.
Vectors are a broad mathematical concept used for various purposes across multiple fields.
Vector embeddings are a particular application of vectors in the domain of machine learning and AI.
What is the purpose of vector embeddings?
Machine learning models are designed to uncover patterns and relationships. They map complex entities, like text or images, to points within a vector space. We call these vector embeddings.
Vector embeddings, also called just embeddings, represent non-numeric data in a numerical format while preserving the semantic meaning and relationships of these non-numeric entities. Their goal is to allow computational models in machine learning and natural language processing (NLP) to "understand" similarities and differences between entities.
What is vector space embedding?
In a vector space, similar entities are positioned closely together, indicating their semantic or contextual similarity. For instance, in the context of word embeddings, words with similar meanings are embedded near each other in the vector space.
This spatial configuration is what enables embeddings to effectively capture and organize the semantic relationships between entities, a concept known as the semantic space.
What is the semantic space?
The semantic space is like a virtual landscape that each large language model (LLM) builds as it trains. During this training phase, the model analyzes huge amounts of data to represent and understand language. The diversity and nature of the information it absorbs play a significant role in shaping this semantic space, which in turn influences how the LLM interprets and generates language.
Given the intricate nature of the data to be transformed, vector embeddings require multidimensional spaces to encompass the depth of these relationships and nuances. Depending on the complexity of the features they are meant to capture and the size of the dataset involved, these spaces can span a wide range, from dozens to thousands of dimensions.
This multi-dimensional space allows algorithms to interpret and process complex data in a way that mirrors human intuition and understanding.
Illustrating the semantic space
Let’s illustrate the semantic space with a very simple example. Consider a diagram with three axes corresponding to the following semantic properties: feline, juvenile, and canine.
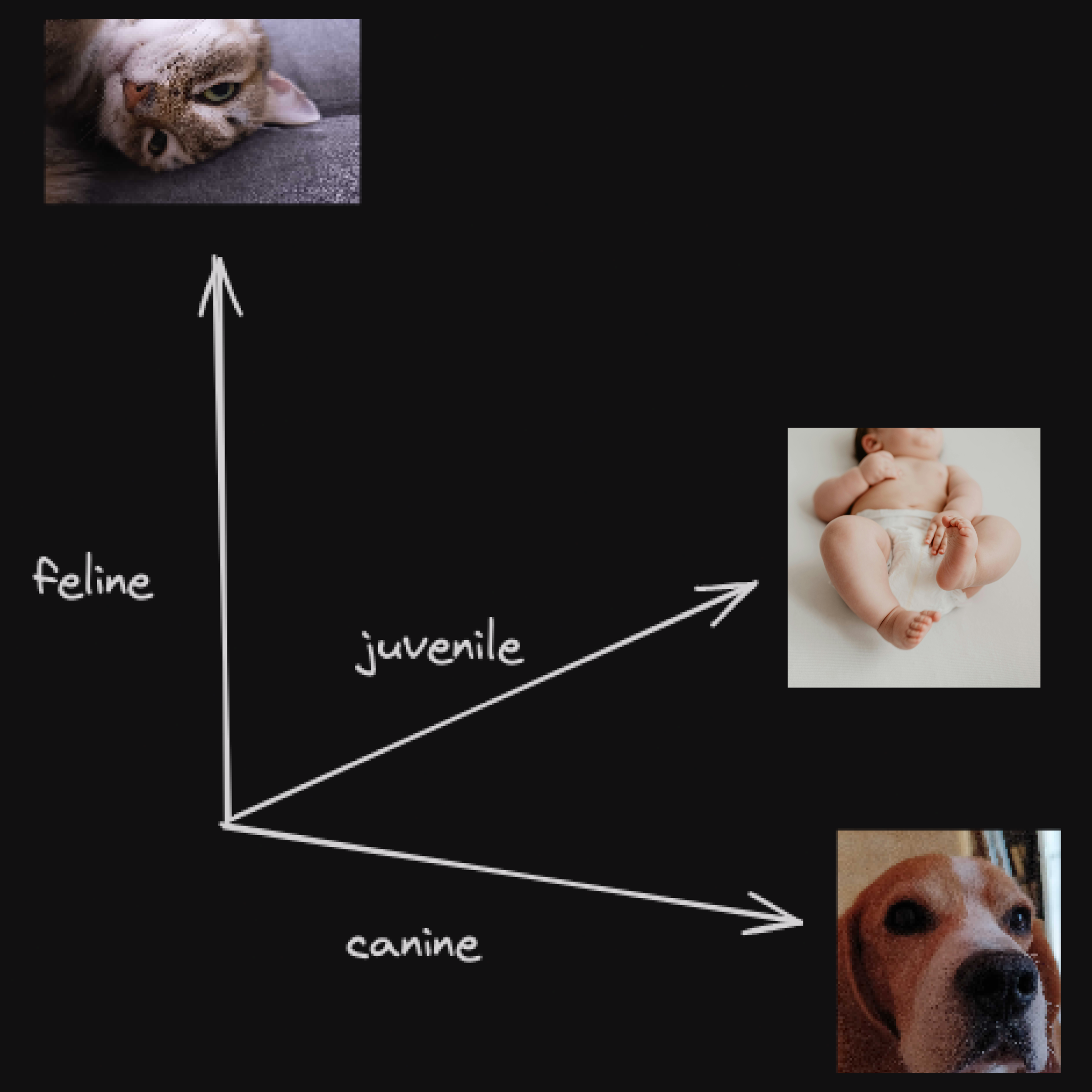
- On the
felineaxis, we have thecat - On the
juvenileaxis, thebaby - On the
canineaxis, we have thedog
By combining these axes, we can find intersections that give us more specific entities:
Felineandjuvenilecombined give us thekittenJuvenileandcaninecombined give us thepuppy
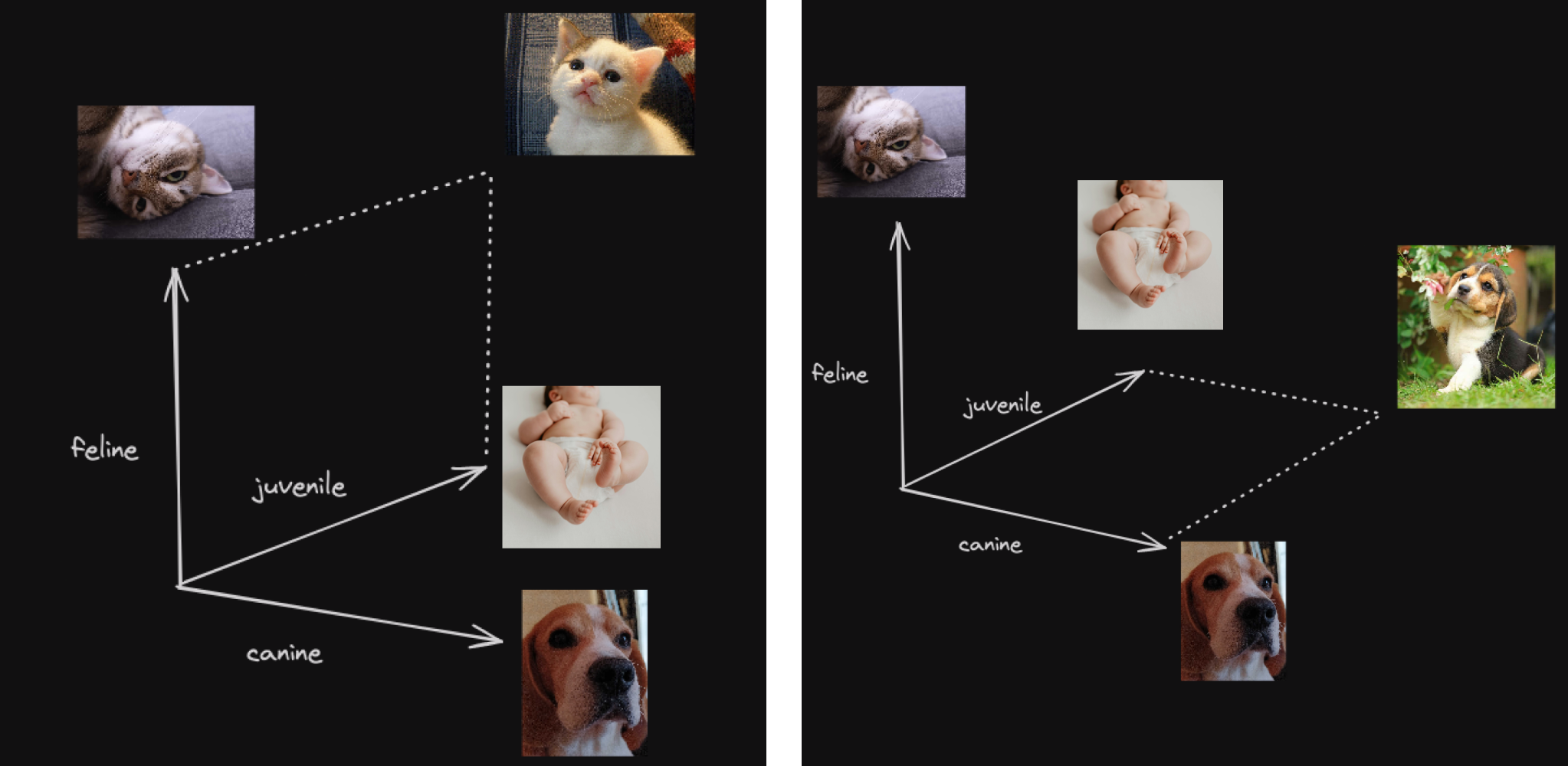
By assigning numerical values to these properties, we can construct a simple semantic space:
Embedding vectors in the semantic space
In reality, the semantic space is more complex, and properties are not always clearly defined. We don’t know if this is actually the canine property, but it’s correlated to something canine, and the dog ranks very high on this property. The numbers are not 1 or 0 but some real numbers. This complexity allows for a nuanced understanding of how words and concepts relate to each other. The actual semantic space could look like the following:
From these detailed values, vector embeddings are created, capturing the essence of each word in a multidimensional vector, such as [0.95973, 0.12, 0.22] for dog. These vectors do more than just position words in a space; they build a detailed network of meanings, with each aspect designed to reveal a bit of what the word really means. The specific dimensions and what they represent can vary from one model to another, reflecting the complexity of the semantic meanings they encapsulate.
Conclusion
Vector embeddings are numerical representations of complex, non-numerical data. They are generated by machine learning models using vectors of real numbers. Embedded in a high-dimensional space, these vectors encapsulate the original data’s relationships and characteristics in a format suitable for computation.
Vector databases, like Meilisearch, are the go-to for working with embeddings, as they facilitate similarity searches, also known as semantic searches, which allow identification of items that are semantically similar based on their vector representations.
AI Search is coming to Meilisearch Cloud, join the waitlist:
Meilisearch is an open-source search engine that not only provides state-of-the-art experiences for end users but also a simple and intuitive developer experience.
A long-time actor in keyword search, Meilisearch enables users to address search use cases by building upon AI-powered solutions, not only supporting vector search as a vector store but also by providing hybrid search. This hybrid approach blends full-text search with semantic search, enhancing both the accuracy and comprehensiveness of search results.
For more things Meilisearch, you can join the community on Discord or subscribe to the newsletter. You can learn more about the product by checking out the roadmap and participating in product discussions.