

Search bars are an integral part of browsing the web. Whether we are shopping for clothes, enjoying music, or planning a vacation, there is always a dedicated search engine at work to simplify our lives. Have you ever wondered how these search engines actually work? In this article, we will delve into the inner workings of one of them: Meilisearch.
Indexing time: from data to documents
Indexing is a fundamental process that encompasses the collection, parsing, and storage of data for subsequent retrieval. It plays a crucial role in enabling search engines to deliver fast and relevant results.
A performant storage engine
Meilisearch stores data in the form of discrete records called "documents," which are grouped together into collections known as "indexes." Under the hood, Meilisearch uses the LMDB (Lightning Memory-Mapped Database) key-value store which has proven stability and extensive usage in database applications. As the name implies, key-value stores are storage systems that organize data as a collection of key-value pairs.
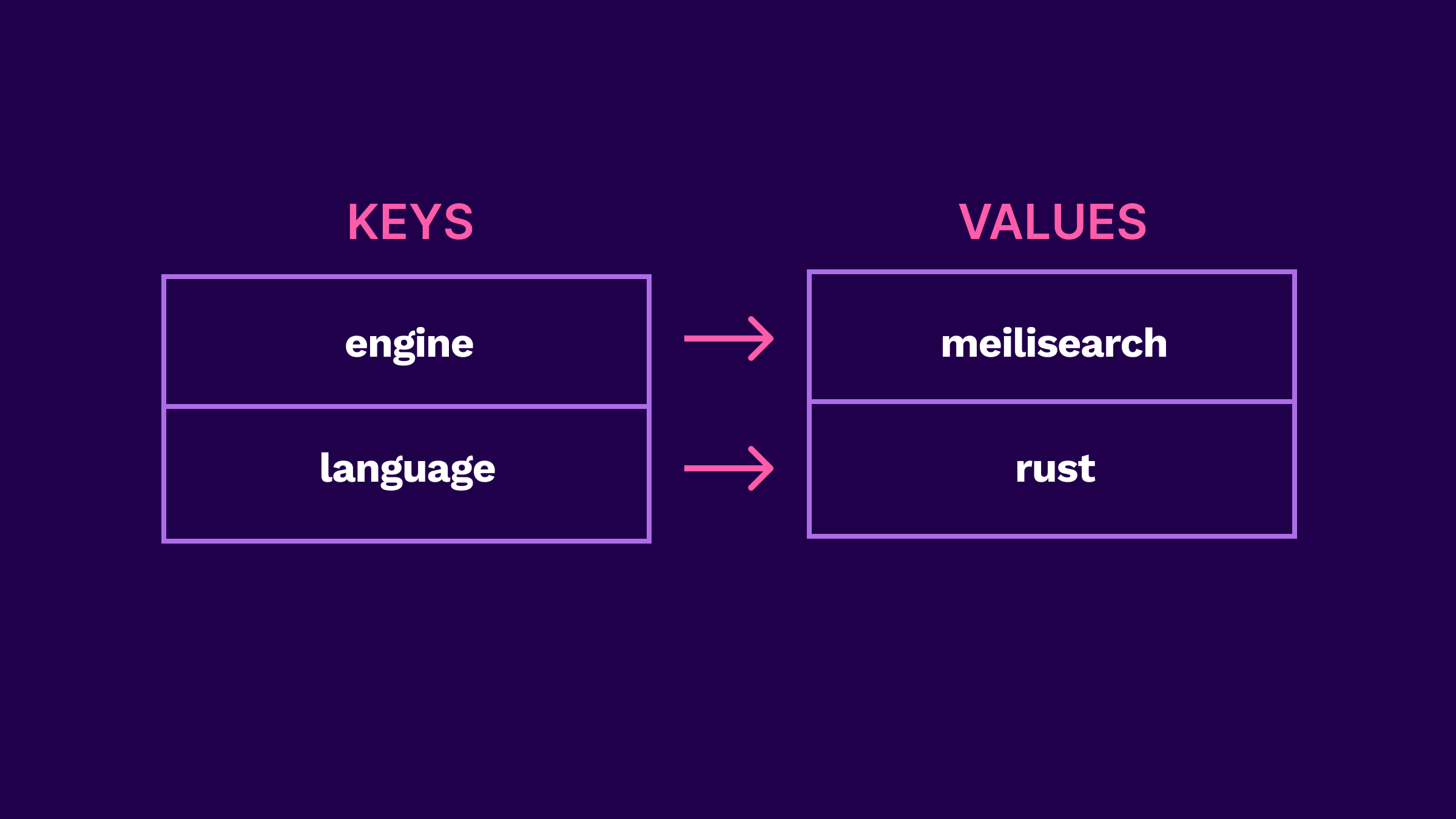
Key-value stores offer flexibility, fast access times, and efficient performance, contributing to quick and responsive interactions for users. By permitting only a single writing process at a time, LMDB avoids synchronization-related issues. As a result, it enables unlimited concurrent readers to have fast access to up-to-date, consistent data.
Before storing data in its key-value store, Meilisearch must preprocess it thoroughly. That’s where tokenization comes in.
From words to tokens
Tokenization involves two main processes: segmentation and normalization.
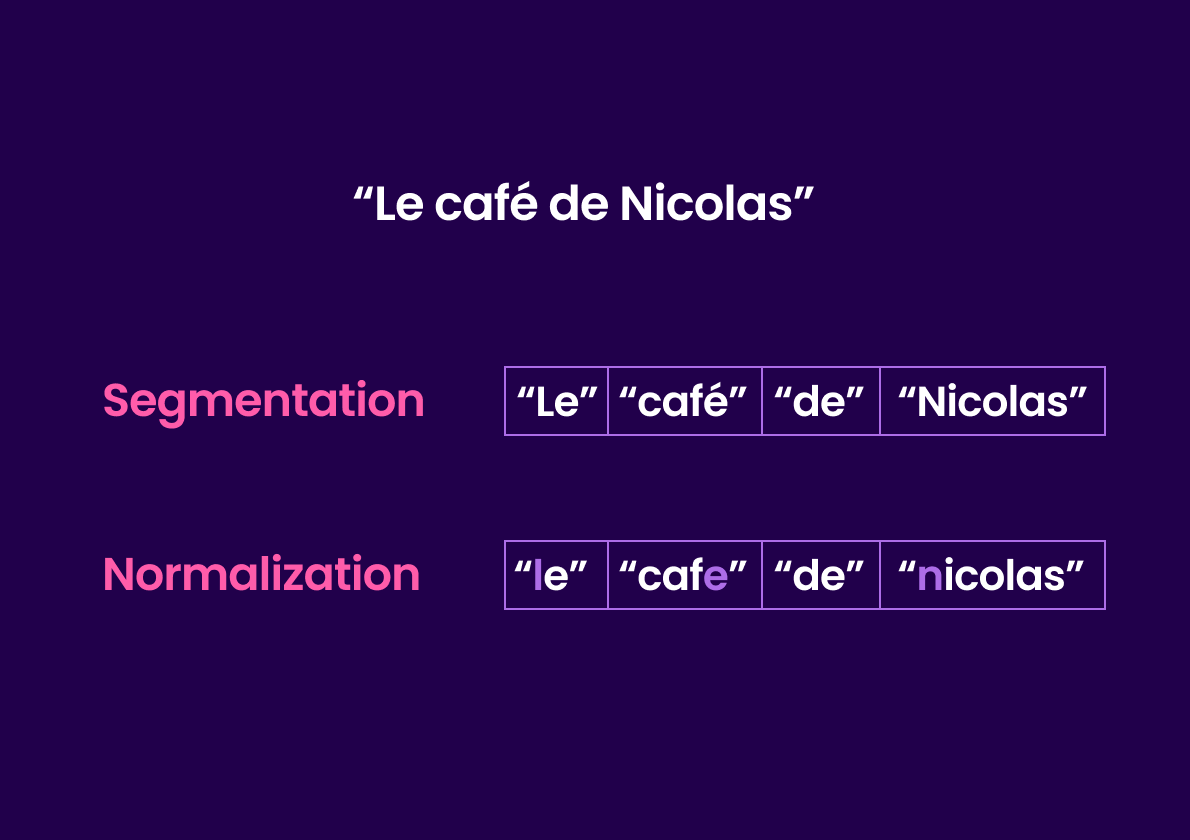
Segmentation consists in splitting a sentence or phrase into smaller units called tokens.
Meilisearch uses (and maintains) the open-source tokenizer named Charabia. The tokenizer is responsible for retrieving all the words (or tokens) from document fields.
Then comes normalization. Words are normalized based on each language’s particularities. For a romance language like French, this process includes setting the word in lowercase letters and removing diacritical marks such as accents. For instance, a sentence like “Le café de Nicolas” is transformed into “le cafe de nicolas”.
After segmenting and normalizing words, the engine needs to classify them. Using the appropriate data structure to organize tokens is crucial for performance. This will later allow swift retrieval of the most relevant search results.
Storing tokens
Modern full-text search engines like Meilisearch come with features such as prefix search, typo tolerance, and geo search. Each data structure has its own advantages and disadvantages. When designing the search engine, our team carefully selected the ones best suited to enable these features without compromising on speed.
Throughout this section, we will explore which data structures powers Meilisearch.
Inverted index
First and foremost, we need to talk about inverted indexes. Without a doubt, it’s the data structure that stands out by its importance. Meilisearch uses it to return documents fast upon search.
An inverted index maps each word in a document to the set of documents where that term appears along with additional information like their position in the document.
![Given the following documents: { “id”: 1 "title": "Hello world!" }, { “id”: 2 "title": "Hello Alice!" }. The inverted index would look like this: "alice" -> [2], "hello" -> [1,2], "world" -> [1]](https://blog.meilisearch.com/content/images/2023/06/Inverted-index-3.png)
By storing words once and associating them with the documents where they appear, inverted indexes leverage the redundancy of terms across documents. Thanks to this, Meilisearch does not need to browse all documents in order to find a given word, resulting in faster searches.
Meilisearch creates approximately 20 inverted indexes per document index, making it one of the data structures with the highest number of instances. Indeed, to provide a search-as-you-type experience, the engine needs to precompute a lot at indexing time: word prefixes, documents containing filterable attributes, and more. For a better understanding of how inverted indexes work read more on indexing best practices.
Roaring bitmap
Roaring bitmaps are compressed data structures designed for efficiently representing and manipulating sets of integers.
Meilisearch uses roaring bitmaps widely throughout its inverted indexes to represent document IDs. Roaring bitmaps offer a space-efficient way to store large sets of integers and perform set operations like union, intersection, and difference. These operations play a crucial role in refining search results by allowing the inclusion or exclusion of specific documents based on their relationship with others.
Finite-state transducer
A finite-state transducer (FST) is a structured data representation ideal for performing string-matching operations. It represents a sequence of states ordered from smallest to largest, with words arranged in lexicographic order.
A finite-state transducer is also called a word dictionary because it contains all words present in an index. Meilisearch relies on the utilization of two FSTs: one for storing all words of the dataset, and one for storing the most recurrent prefixes.
FSTs are useful because they support compression and lazy decompression techniques, optimizing memory usage and storage. Additionally, by using automata such as regular expressions, they can retrieve subsets of words that match specific rules or patterns. Moreover, this enables the retrieval of all words that begin with a specific prefix, empowering fast, comprehensive search capabilities.
The FST, with its compact design, presents the added advantage of being a smaller data structure than the inverted index. As we will see later, this contributes to faster and more efficient reading operations. You can learn more about the topic in this comprehensive article on finite-state reducers.
R-tree
R-trees are a type of tree used for indexing multi-dimensional or spatial information. Meilisearch leverages R-trees to power its geo search functionality.
The R-tree associates geographical coordinates with the identifiers of the document to which it belongs. By organizing coordinates this way, it enables Meilisearch to perform spatial queries with remarkable efficiency. These queries allow users to find nearby points, points within a specific area, or points that intersect with other spatial objects.
Search time: query processing
Modern search experiences only require you to start typing to get results. To achieve this search-as-you-type experience, Meilisearch precomputes a list of the most frequent prefixes.
To be tolerant to typos, Meilisearch uses finite-state transducers in conjunction with the Levenshtein algorithm. This algorithm calculates the Levenshtein distance which can be thought of as the cost of transforming a string into another. In other words, it quantifies the number of transformations required for a word to be converted into another word.
In the context of the Levenshtein algorithm, possible transformations are:
- insertions, e.g. hat -> chat
- deletions, e.g. tiger -> tier
- substitutions, e.g. cat -> hat
- transpositions or swaps, e.g. scared -> sacred
FSTs generate all possible variations of a word within a specified edit distance, enabling the engine to calculate the Levenshtein distance and accurately detect typos by comparing user input against a dictionary of valid words.
It becomes apparent that there are many factors to consider when processing a search request. Has the user finished typing? Are there typos in the query? Which documents should appear first in the search results?
Let’s discuss how Meilisearch processes search queries and how it refines and sorts search results.
Query graph
Each time it receives a search query, Meilisearch creates a query graph representing the query and its possible variations.
To compute these variations, Meilisearch applies concatenation and splitting algorithms to the query terms. The variations considered also include potential typos and synonyms–if the user set them. As an example, let’s examine the query: the sun flower. Meilisearch will also search for the following queries:
the sunflower: concatenationthe sun flowed: substitutionthe sun flowers: addition
Consider now a more complex query: the sun flower is facing the su, the query graph should look like this:
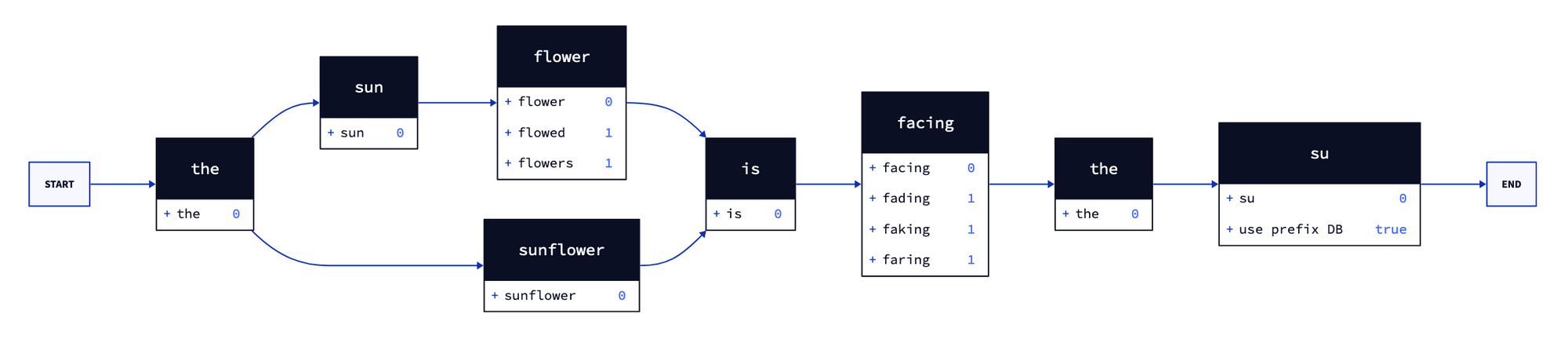
As illustrated above, the graph represents different interpretations of the search query. The engine precomputes the word variations (and their cost) for each query term. Moreover, it detects whether the last query term is a prefix (not followed by a space), thus signaling the need to consult the prefix database.
So how does the engine utilize a query graph?
As we saw earlier, during the indexing process, Meilisearch identifies all documents that have filterable attributes, such as genre. Subsequently, it generates a list of document IDs associated with each attribute value, like comedy or horror. First of all, when a filter is applied, Meilisearch narrows down the potential results to the document IDs that fulfill the filter criteria.
Next, it uses the query words and the variations generated in the query graph and searches for matching words in the finite-state transducer (that is, our word dictionary). If the word is considered a prefix, it will also look it up in the prefix FST.
When encountering words in a FST, it searches them within the inverted index—which contains a mapping of words to document IDs— to retrieve the corresponding document IDs.
Finally, the engine performs an intersection to identify the documents that contain the words in the query graph and meet the filter criteria.
Let's take an example to better understand query processing: suppose you have a dataset of songs. The search query is John Lennon. The user wants to retrieve only songs released between 1957 and 1975.
First, Meilisearch retrieves the document IDs of songs within that time frame. Then, after checking in the FST that the words in the query graph exist, Meilisearch retrieves the IDs of the documents that contain either John, Lennon, or both. It also retrieves the possible variations, but we are not including them in this example for the sake of simplicity.
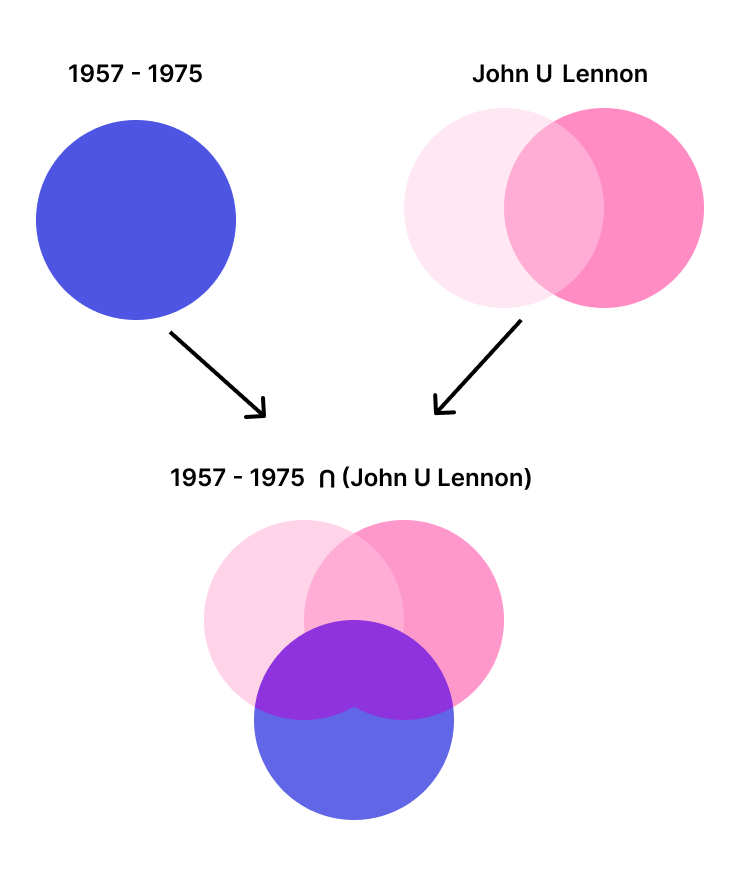
Finally, the intersection of the two sets of document IDs is taken (the purple area in the diagram.) This means only document IDs that appear in both sets are kept. In other words, Meilisearch retains the document IDs of songs released between 1957 and 1975 that contain either John, Lennon, or both.
What happens when several documents match the search query, how does the engine decide which one to return first? Which one is more relevant? Let's explore the rules allowing Meilisearch to determine how to rank results.
Relevancy
As we discussed earlier, the query graph includes possible variations of words. As a result, Meilisearch will also return documents with an artist, such as John Lebon, as part of the search results.
Fortunately, the query graph not only accounts for word variations but also assigns them the Levenshtein cost, which, among other factors, helps Meilisearch determine the relevancy of the search results.
Meilisearch sorts documents in the search results using bucket sort. This algorithm allows ranking documents based on a set of consecutive rules. By default, Meilisearch prioritizes rules as follows:
- Words: sorts documents based on the number of matched query terms, with documents containing all query terms ranked first
- Typo: sorts documents based on the number of typos, with documents matching query terms with fewer typos ranked first
- Proximity: sorts documents based on the distance between matched query terms. Documents where query terms occur close together and in the same order as the query string are ranked first
- Attribute: sorts documents based on the ranking order of attributes. Documents containing query terms in more important attributes are ranked first. Documents with query words at the beginning of attributes are considered more relevant than those with query words at the end
- Sort: sorts documents based on the user-defined parameters set at query time, if active
- Exactness: sorts documents based on the similarity of matched words with the query words
Meilisearch applies these rules sequentially, sorting results step by step. If two documents are tied after one rule, it uses the next rule to break the tie.
By default, Meilisearch returns up to 1000 documents per search, prioritizing delivery of the most relevant results rather than all matching results. In other words, Meilisearch prioritizes efficiency and relevance over exhaustive results to ensure an optimized search experience.
Conclusion
Search engines are complex systems that encompass multiple interconnected components, all working together to deliver a seamless search experience. While the inner workings may differ among search engines, we have explored the underlying mechanisms that power a modern search engine.
Meilisearch is currently exploring the vast realm of semantic search. AI-powered search is reshaping the way we understand queries and documents, opening up new possibilities and use cases. If you’re eager to experience it firsthand, we invite you to try our vector search prototype—your feedback would be greatly valuable!
Meilisearch is an open-source search engine that not only provides state-of-the-art experiences for end users but also a simple and intuitive developer experience. Do you want to see Meilisearch in action? Try our demo. You can also run it locally or create an account on Meilisearch Cloud.
For more things Meilisearch, you can join the community on Discord or subscribe to the newsletter. You can learn more about the product by checking out the roadmap and participating in product discussions.