

Today marks the launch of Meilisearch v0.21, our first new release since March 2021. As you might expect, this one packs a whole lot of changes to our search engine, both big and small. You can check our exhaustive changelog outlining all breaking changes and download the binaries here, but in this post we wanted to take a closer look at some of the most important updates.
Search performance
First, one of the best news we could give you: v0.21 is the fastest Meilisearch release (so far). How fast? Our tests using a 1GB dataset with 115 million documents indicate that complex queries return results up to ten times faster than v0.20; filtering those results, previously a slow operation, takes a maximum of 50ms.
Refactor
Clémentine already wrote about why we chose to refactor fundamental parts of our core engine, but in case you missed it: it became increasingly hard for us to keep our code easy to read for external contributors and to add new features without negatively impacting performance.
We are very proud of what we accomplished in these months, not only because we managed to greatly improve Meilisearch's performance, but also because we know our search engine has a new, rock-solid foundation.
Facets and filters
Some of the biggest visible (and breaking) changes in v0.21 concern facets and filters.
First of all, the search parameters filters and facetFilters have been replaced by filter. This new parameter allows you to refine search results based on document attributes whose values are either numbers or strings.
$ curl 'http://localhost:7700/indexes/movies/search' \
--data '{ "q": "thriller", "filter": ["genres = Horror", "genres = Mystery"]}'To use an attribute with the filter search parameter, you must first add it to the new filterableAttributes index setting. filterableAttributes works exactly like and replaces the attributesForFaceting index setting.
$ curl \
-X POST 'http://localhost:7700/indexes/movies/settings' \
--data '{
"filterableAttributes": [
"director",
"genres"
]
}'
Meilisearch no longer distinguishes between facets and filters: you can use the new filter search parameter and the filterableAttributes index setting to create faceted search interfaces.
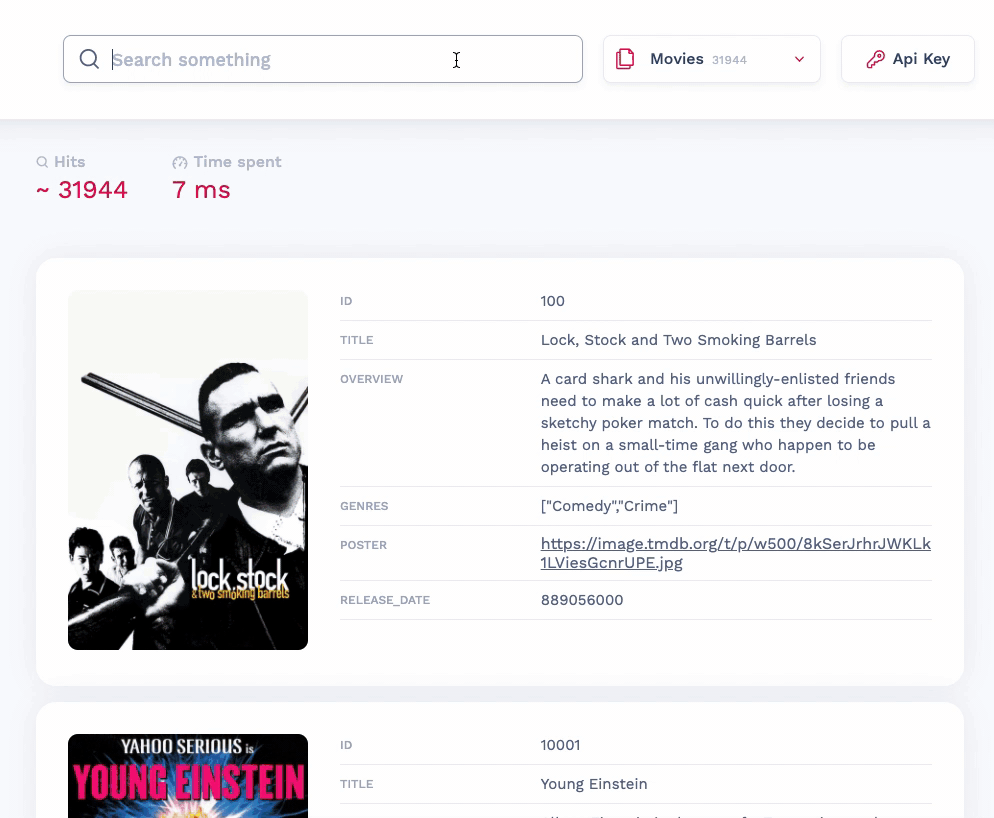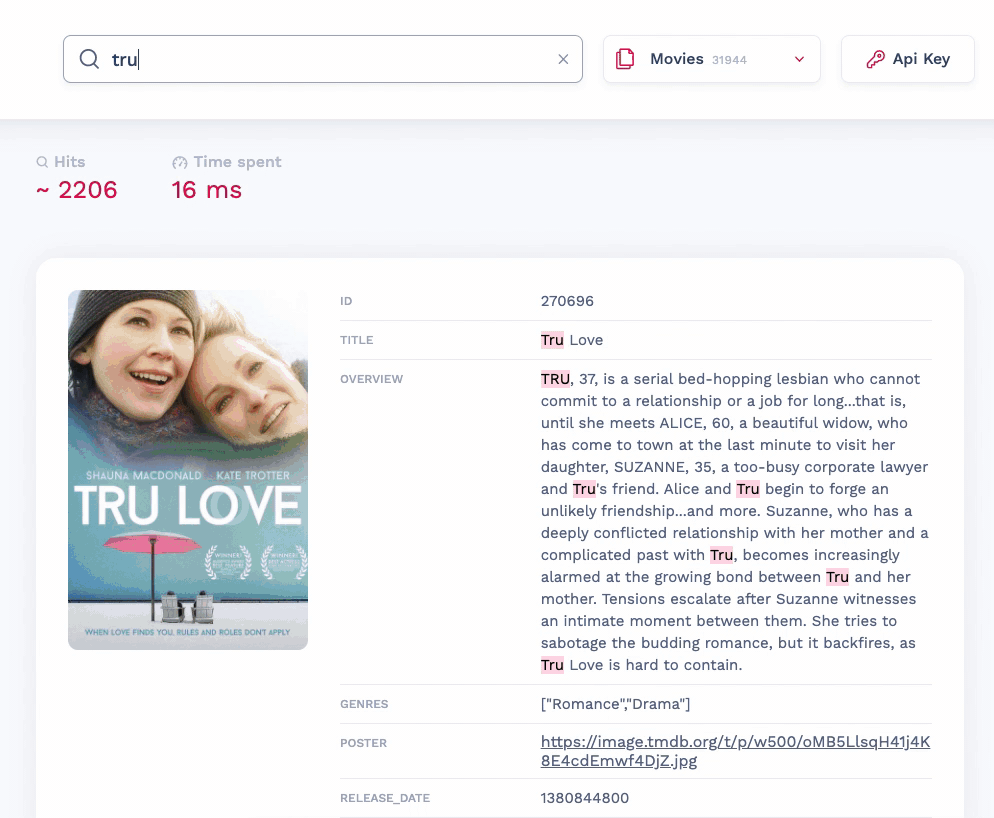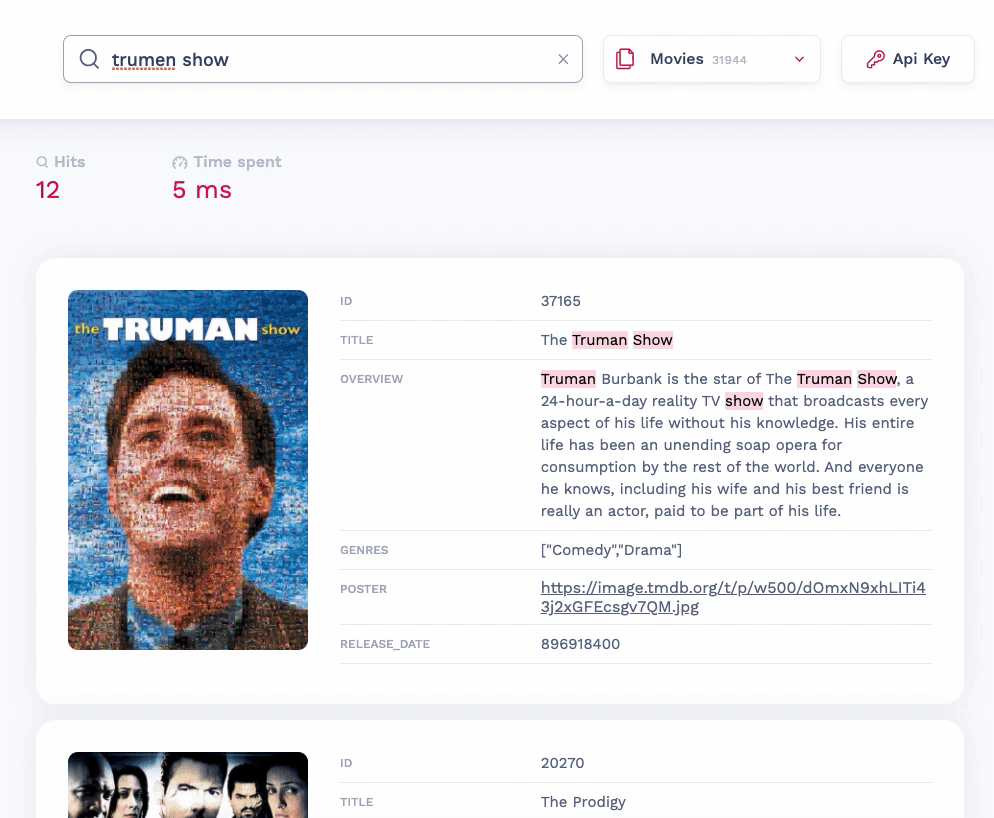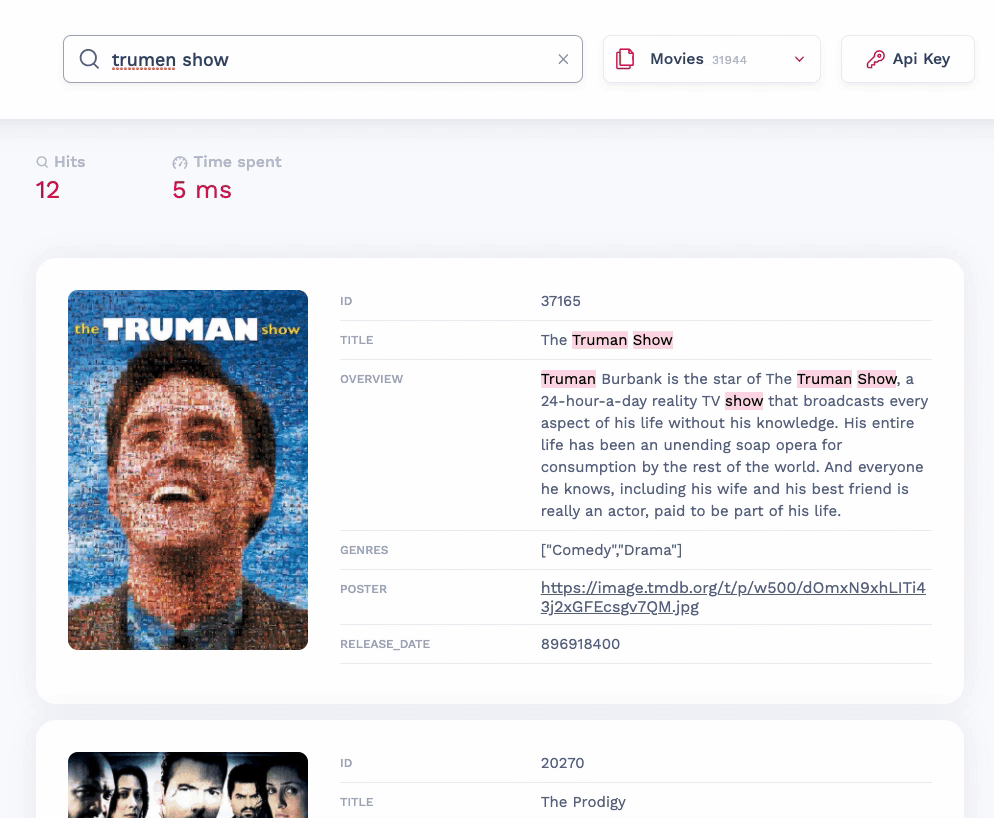
Phrase search
Meilisearch v0.21 supports phrase searches. If you enclose one or more search terms in double quotes (for example, “african-american poet” or “John Waters”), Meilisearch will only return documents that contain those terms exactly as they were written and in the order they were given. Phrase searches are a great way to make a query more precise and come in handy when you know your search should only get one result, such as when looking for a book using its ISBN number.
$ curl 'http://localhost:7700/indexes/movies/search' \
--data '{ "q": "\"John\" Waters" }'Web interface
In case you didn't know, Meilisearch automatically creates a web interface when you launch an instance in development mode so you can test our search engine right away. We have updated this interface so it's even easier to use (and nicer to look at)!
New telemetry page and simpler analytics settings
By default, Meilisearch collects anonymized data from all instances using our search engine. We have made it easier to disable this behavior and added a new page to our docs explaining exactly what data we collect and how we use it. Privacy is an important issue for us, so please feel free to share any comments, concerns or suggestions you may have.
$ ./meilisearch --no-analytics=trueHighlight matches in array and object fields
Meilisearch v0.20 allowed you to highlight matched search terms in string fields so users could see where exactly a term was found within a document. In v0.21, we have extended this functionality to work with arrays of strings and nested objects. Like before, you can find the highlighted matches inside the _formatted object of each returned document.
$ curl 'http://localhost:7700/indexes/movies/search' \
--data '{
"q": "adventure",
"attributesToHighlight": ["title", "genres"]
}'{
"id": "50393",
"title": "The Adventures of Huck Finn",
"overview": "Climb aboard for an extraordinary version of Mark Twain's sweeping adventure when Walt Disney presents The Adventures of Huck Finn, starring Elijah Wood.",
"release_date": 733712400,
"genres": ["Adventure","Family"]
"_formatted": {
"id": "50393",
"title": "The <em>Adventures</em> of Huck Finn",
"overview": "Climb aboard for an extraordinary version of Mark Twain's sweeping adventure when Walt Disney presents The Adventures of Huck Finn, starring Elijah Wood.",
"release_date": 733712400,
"genres": ["<em>Adventure</em>","Family"]
}
}_formatted.Other changes
- You might notice minor performance improvements in the indexer: this is a work-in-progress and we are eager to have your feedback on it
- The
wordsPositionranking rule has been merged intoattribute max-mdb-sizehas been renamed tomax-index-size- It is now possible to specify
max-index-sizeandhttp-payload-limit-sizeusing human-readable units such asKborGb - We have removed the limit of 200 indexes per instance
Bug fixes
- Windows instances no longer immediately occupy the maximum index size on launch
- The ranking rule
Wordsnow works as expected - Dumps now export all document fields correctly, regardless of whether they are present in
displayedAttributes
Contributors
A lot of this was made possible thanks to our community: we are honestly humbled by your generosity. Meilisearch is a better search engine because of you.
We want to send a special shout out to @sanders41 and @bb: your bug reports and feedback were super helpful!
Finally, a big thank you to @shekhirin for all the help with the new search engine implementation.
That's about it for this release! To have a full overview of all changes, breaking and otherwise, you can check out our changelog.