

Full text search refers to matching some or all of a text query with documents stored in a database. Compared to traditional database queries, full text search provides results even in case of partial matches. It allows building more flexible search interfaces for users, thus enabling them to find accurate results more quickly.
From simple in-app search to browsing huge ecommerce catalogs, full text search use cases are numerous. It is so common that Postgres and other relational databases include dedicated APIs for full text search. Unfortunately, Postgres falls short of search-focused databases in multiple areas.
1. Complex setup
To provide relevant results, full text search should tolerate typos, allow synonyms, and allow partial matches. Additionally, results ranking needs to be highly customizable to adapt to a business’s specific needs. Configuring full text search on Postgres comes at the cost of comprehensive configuration and often requires extensions that can’t be used when using managed Cloud services.
Creating database indexes, writing queries, and ranking algorithms quickly overstep domain knowledge and demand expertise in searching, indexing, and linguistics. Optimizing for performance gets even harder when working around constraints from mixed-and-matched extensions aimed at coping with Postgres full text search limitations.
Conversely, a search-focused database comes with state-of-the-art features like typo tolerance, prefix search, fuzzy matching, synonyms, and customizable rankings out of the box.
2. Faceted search
Faceted search allows users to refine search results by broad categories. It’s often used in ecommerce applications. For example, a clothing shop can implement filtering by facets such as brand, size, or rating range.
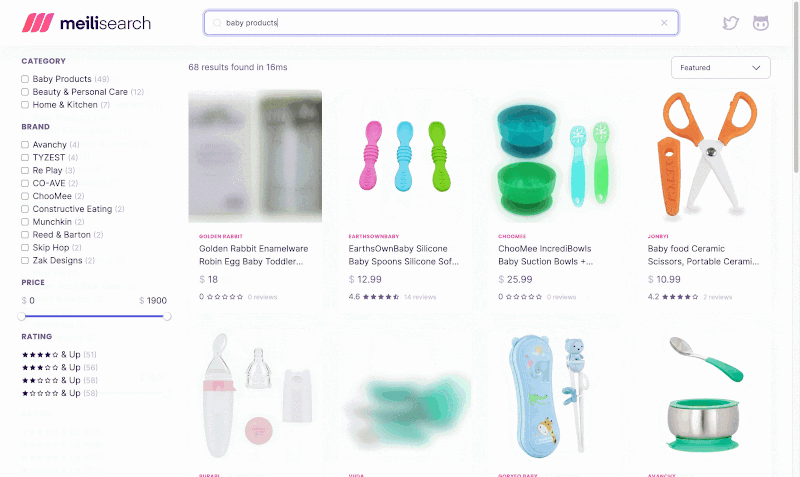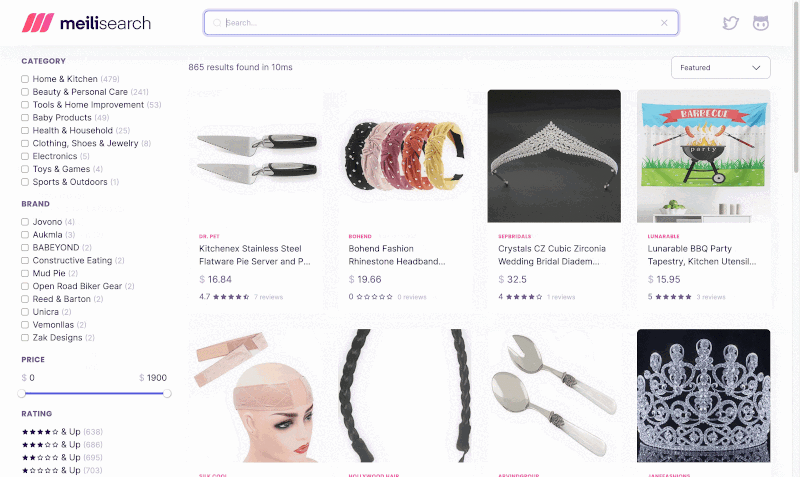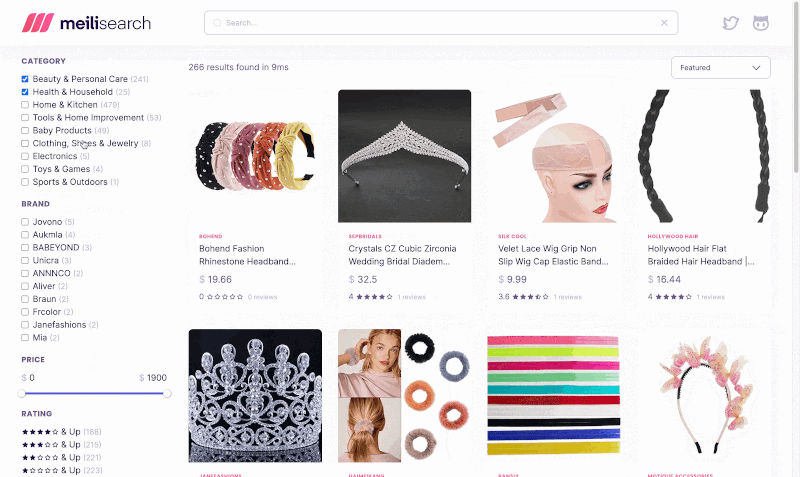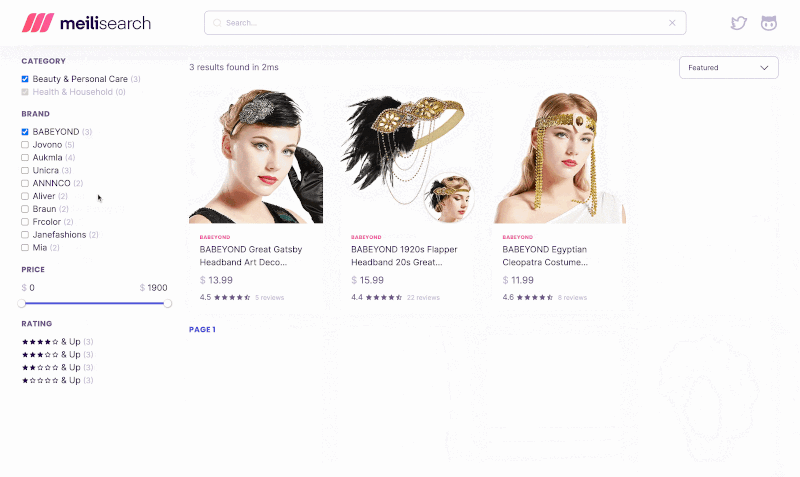
Implementing filtering is tricky enough for a single facet. But facets can take many shapes: category tags, price ranges, or minimum rating. Implementing filtering for all types is very challenging. By all means, the trickiest query to implement is aggregating results to build facet counts. This becomes very resource intensive on large datasets.
The complexity of implementing faceted search with Postgres grows exponentially with the number of facets. Faceted search alone makes a strong selling point for search engines like Elasticsearch or Meilisearch. They come with optimized, first-class APIs to handle facets filtering and counting.
3. Typo tolerance
By default, Postgres full text search cannot handle misspellings. Users commonly install the pg_trgm extension to work around this limitation. (Again, this solution is not always available in managed Postgres.) This extension notably introduces new operators to compare similarity between strings along with search-optimized GIN and GIST indexes.
The new indexes allow more configuration for full text search, but choosing between GIN and GIST indexes is not always trivial. Moreover, the new operators do not take into account word proximity, space separators, or word size. This, in particular, makes it hard to achieve real fuzzy matching with Postgres.
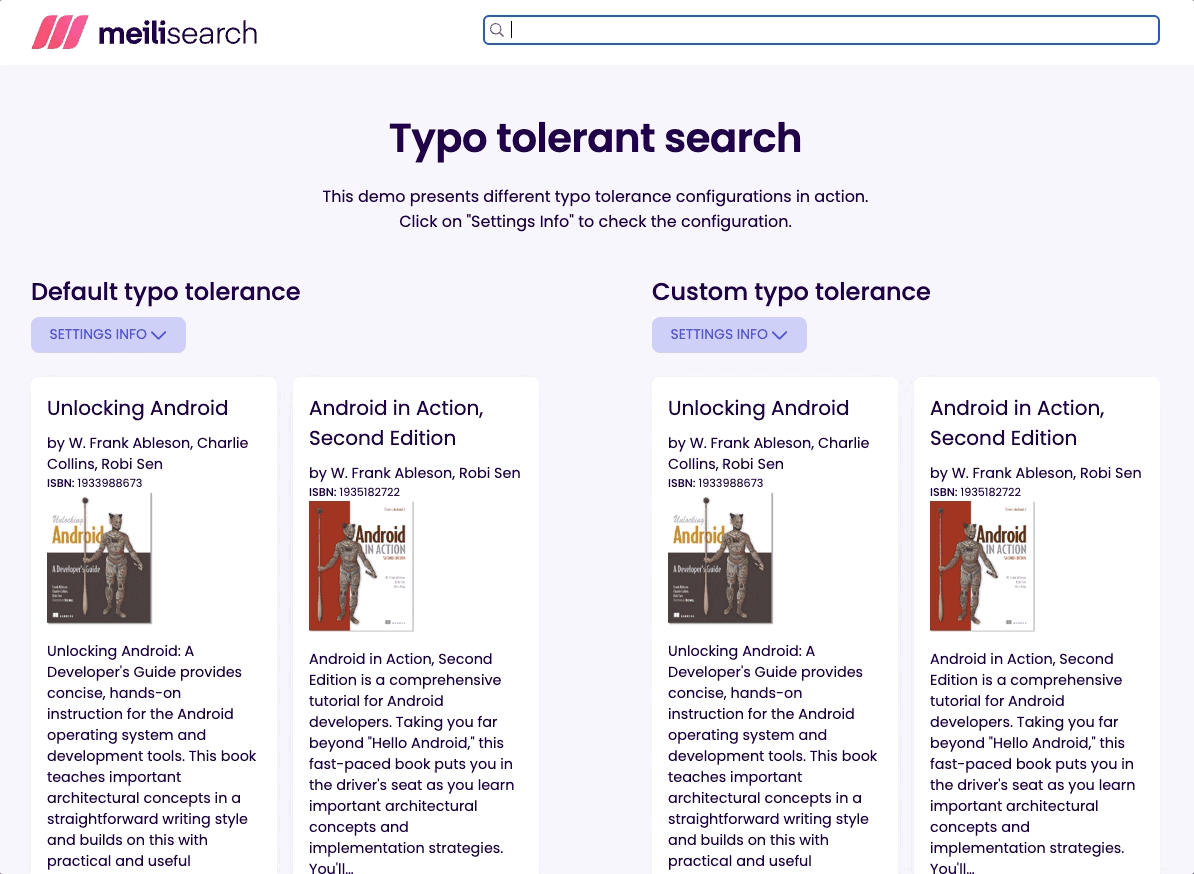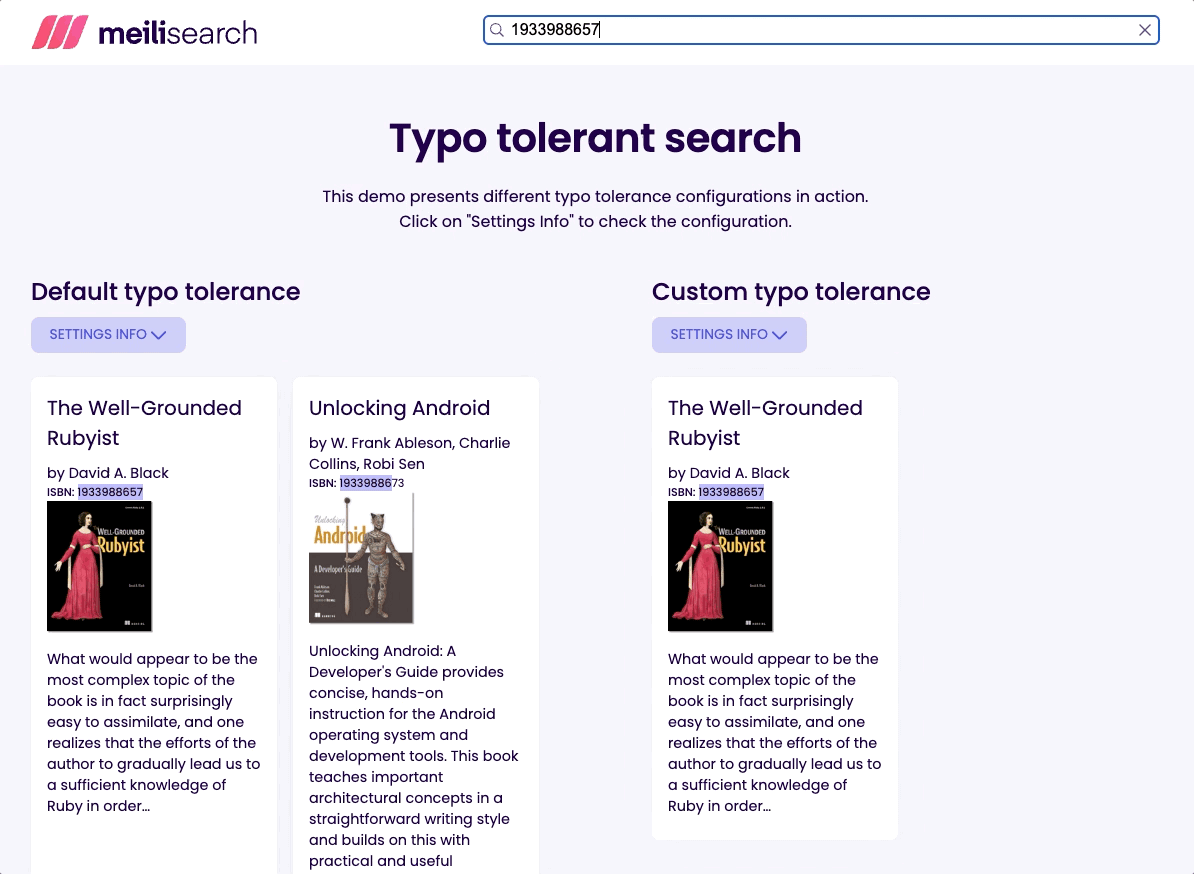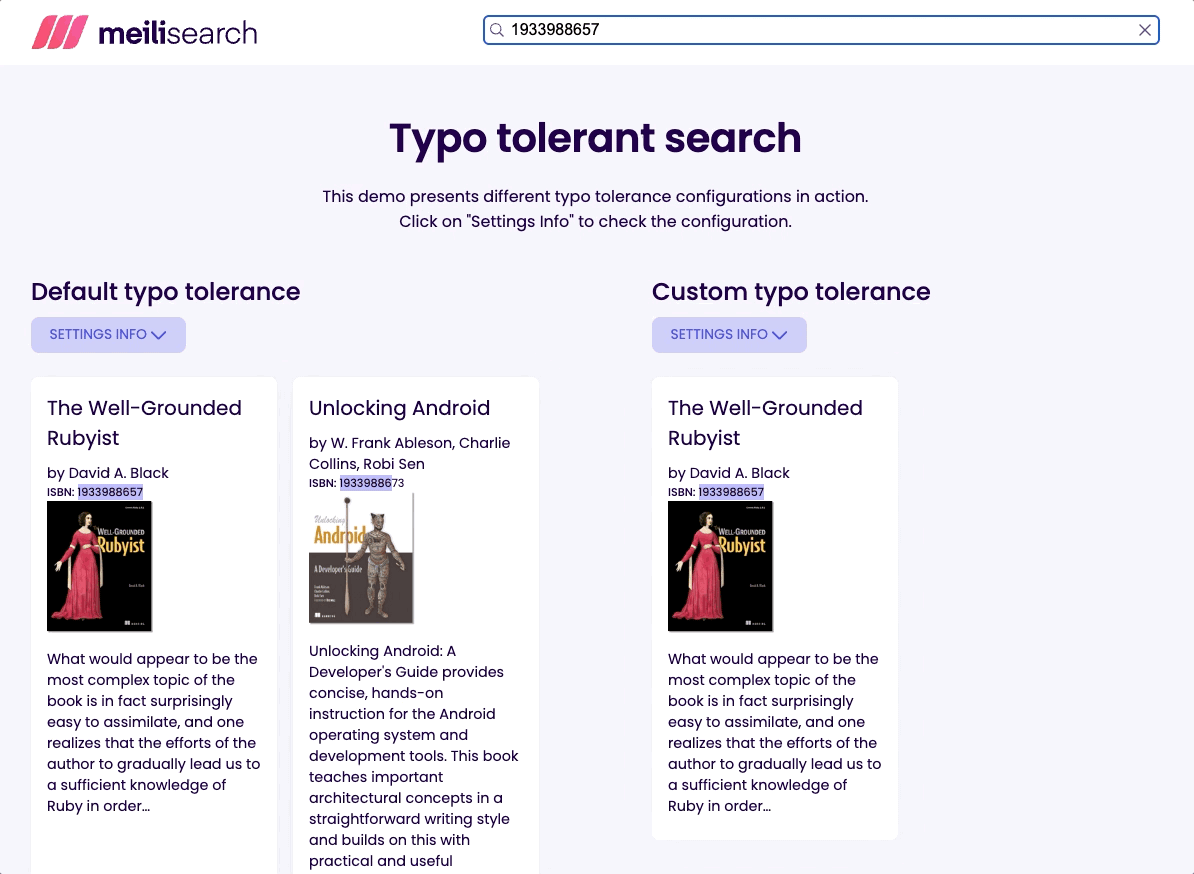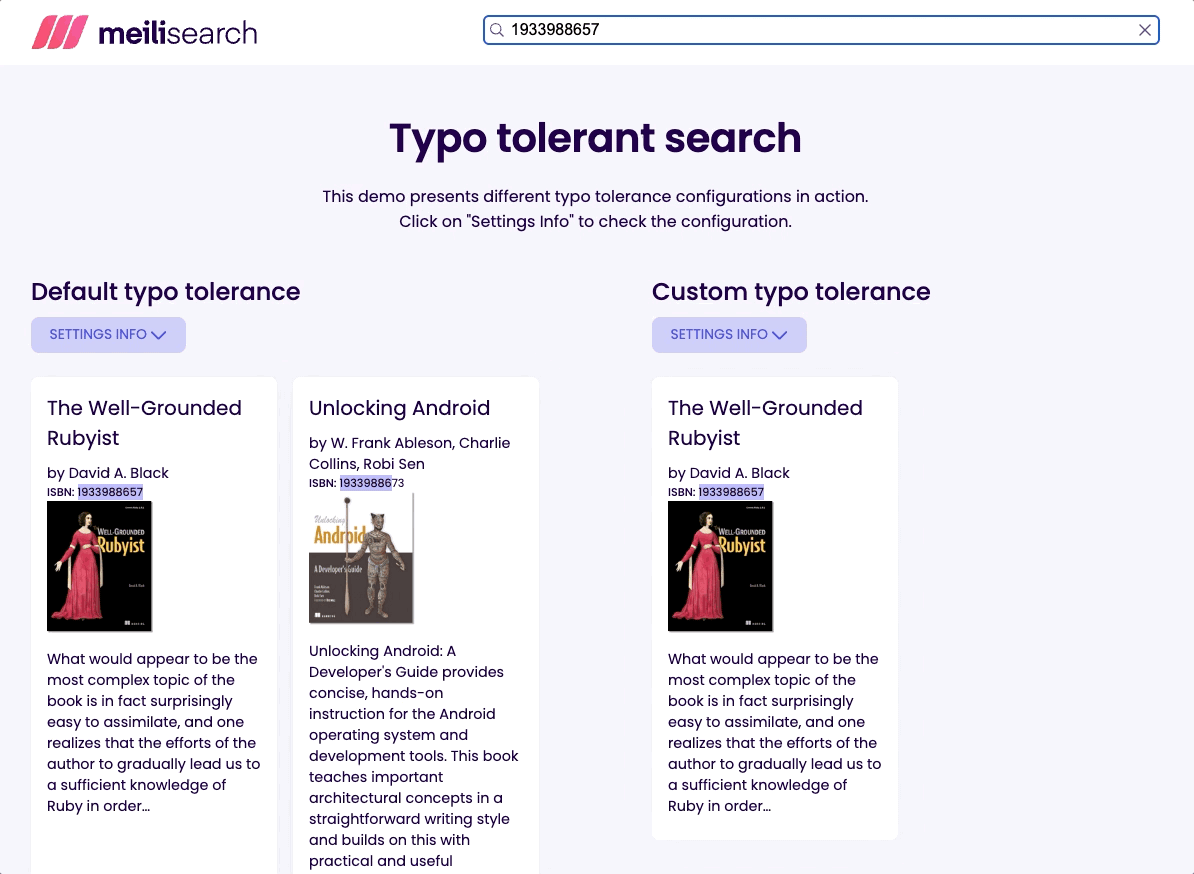
Ideally, a search-focused database should allow configuring different rules for single versus multiple words queries. It is the case of Meilisearch, which allows disabling typos entirely for specific fields. This enables users to search via unique identifiers like a book’s International Standard Book Number (ISBN).
4. Language support
Linguistic specificities vary a lot between languages using the Latin alphabet and others like Arabic or Chinese. As of Postgres 15, full text search dictionaries are unavailable for Simplified and Traditional Chinese, Korean, and Japanese, among others. This means resorting to specific implementations for different languages.
Language support constraints are amplified in managed environments like Amazon RDS where users are unable to access the filesystem. This restricted access prevents them from implementing custom dictionaries, stemmers, synonyms, and more.
Meilisearch comes with optimized language support for Chinese, Japanese, Korean, Hebrew and more, on top of all languages using whitespace to separate words.
5. Paying the backend price
Postgres is a database intended to communicate with server-side languages. When building a public-facing client application, it means building an API on top of the database to communicate with clients. On top of additional development time, creating such a proxy entails further problems.
First comes the issue of latency: making requests to an API that queries the database before returning results is bound to take some time. This does not affect dedicated search engines, as they come with a public API intended to deliver data to end users.
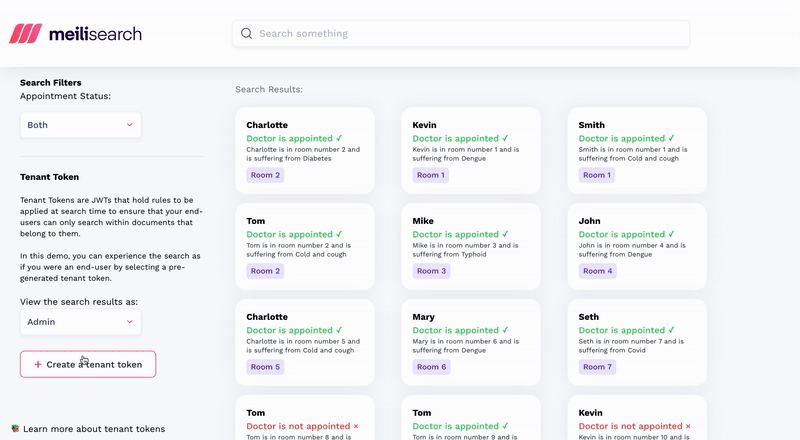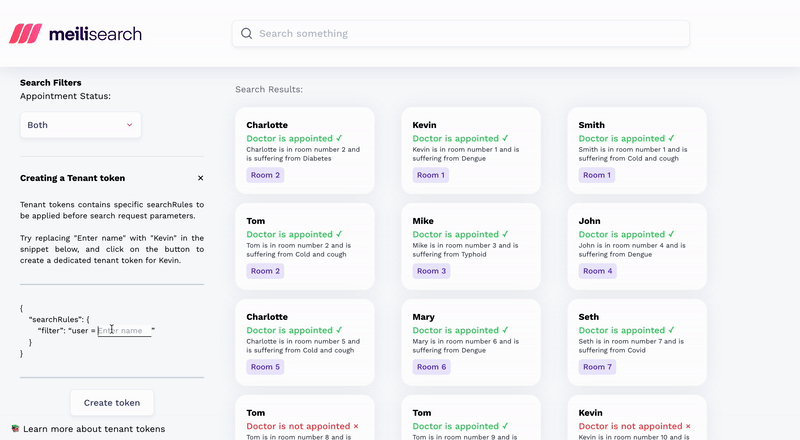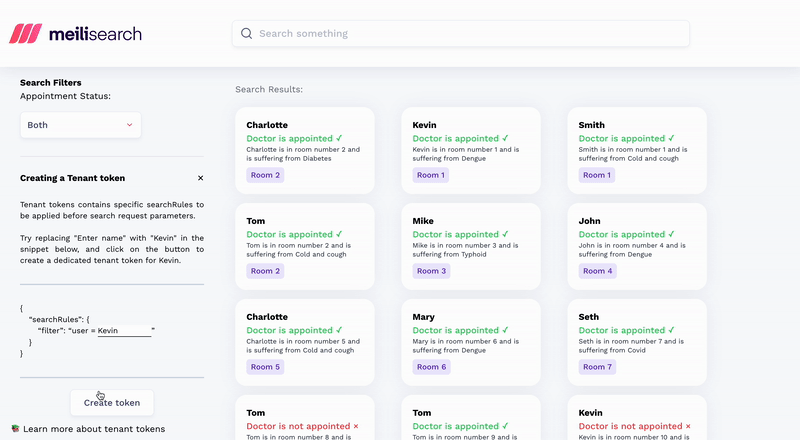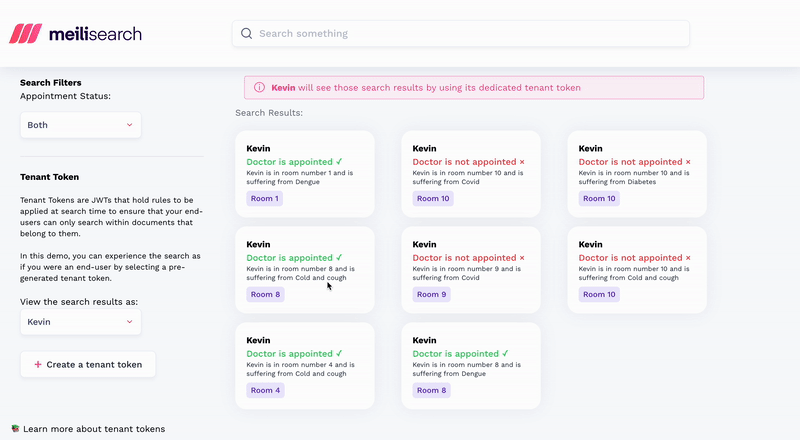
Now comes the second issue: security. Search engines APIs are designed, from the start, for public consumption. And security’s baked in for that use case. By default, API keys restrict search requests, while advanced features like tenant tokens enable multi-tenancy.
6. Scaling limitations
There is a legitimate motive for wanting to keep all data in a single database. But having search-related data in the main database comes with great technical consequences. Full text search queries on large dataset become costly with Postgres, especially when ranking results and computing facet counts.
Monolithic databases often become the bottleneck of applications that need to scale. Don’t add unnecessary search-related costs to this resource when you can avoid it. These costs are only multiplied when building user-facing applications with high traffic.
Unlike relational databases, full text search engines like Meilisearch use inverted indexes. This data structure creates information redundancy to allow quicker information retrieval. It is designed to perform search operations, and will naturally outperform relational databases on large datasets. And, when search usage spikes, there is a single service that needs scaling.
7. Relevancy
As we mentioned earlier, relevant search requires typo tolerance, custom rankings, and synonyms. In modern applications, users expect results to update on each keystroke, which requires prefix searching. But Postgres full text search ts_rank function only allows attribute weighting. When using the pg_trgm extension, developers are left to implement their own sorting based on similarity.
In search-focused databases, the concepts of result ranking, attribute priority, numbers of word matched, and exactness of the query are first-class concepts. They match high-level APIs that allow explicit fine-tuning of search behavior. This makes it easier to make these concepts available to non-tech, business stakeholders. This was cited as a key reason for why Bookshop chose Meilisearch for their ecommerce search.
8. Missing out on InstantSearch libraries
When it comes to search experience, websites and applications often implement the same user interface patterns: a textual search bar, checkbox lists of facets, range sliders, sorting menu, page navigation, etc. The open-source InstantSearch library comes with implementations of all these features in the form of widgets available via SDKs in JavaScript, iOS, and Android.
When time to market is paramount, it’s hard to pass on such niceties. Supported by Algolia, the InstantSearch libraries enjoy wide adoption and several search engine databases come with InstantSearch-compatible APIs. Read our Nuxt guide for ecommerce search to learn how to implement InstantSearch widgets with Vue.
9. Limited Cloud support
Outsourcing the provisioning, maintenance, and scaling of servers is a common strategy in the Cloud era. Instead of managing servers, teams can focus on delivering value to their users. Postgres, like other databases, is available in a wide range of Cloud offerings for managed services. Unfortunately, managed services often come with limitations.
In the case of Postgres, implementing state-of-the-art full text search requires installing extensions. Moreover, fine-tuning language dictionaries and more configuration require access to the file system. Unfortunately, this means that many features are unavailable in Cloud environments.
To enable delegation of infrastructure, search engines often come with dedicated cloud services. Those bespoke platforms do not compromise and allow using the full palette of search features. Moreover, customers can benefit from premium SLAs, support, and other enterprise services tailored to their searching use cases.
Postgres is a great, flexible database that allows the implementation of many custom, all-in-one solutions. Its full text search features might be sufficient for basic search, but it falls short when it comes to real-time search with relevance concerns. These limitations become worse on large datasets. It’s only natural, because Postgres is a database, not a search engine.
Meilisearch is an open-source search engine to build fast and relevant search experiences. It aims at providing state of the art experiences for end users while providing a simple and intuitive developer experience. You can try it by running Meilisearch locally or creating an account for free on Meilisearch Cloud.
Learn more about what Meilisearch can bring to your business
For more things Meilisearch, you can join the community on Discord or subscribe to the newsletter. You can learn more about the product by checking the roadmap and participating in product discussions.